1.1 RISCV ISA特性
- 模块化:riscv不同于x86、mipis-32等增量型ISA,主要采样模块化定制化的思路来装载所需要的指令
- 简洁性:riscv的isa更加简洁,而简单指令比复杂指令更加常用,编译器更倾向于用简单指令代替复杂指令,导致一些复杂指令被设计出来但使用率低下,占用芯片面积
- 性能:在每个程序中简洁 ISA 需要执行的指令比复杂 ISA 多,但前者能通过更高的时钟频率或更小的每指令平均周期数(Cycles Per Instruction,CPI)来弥补。
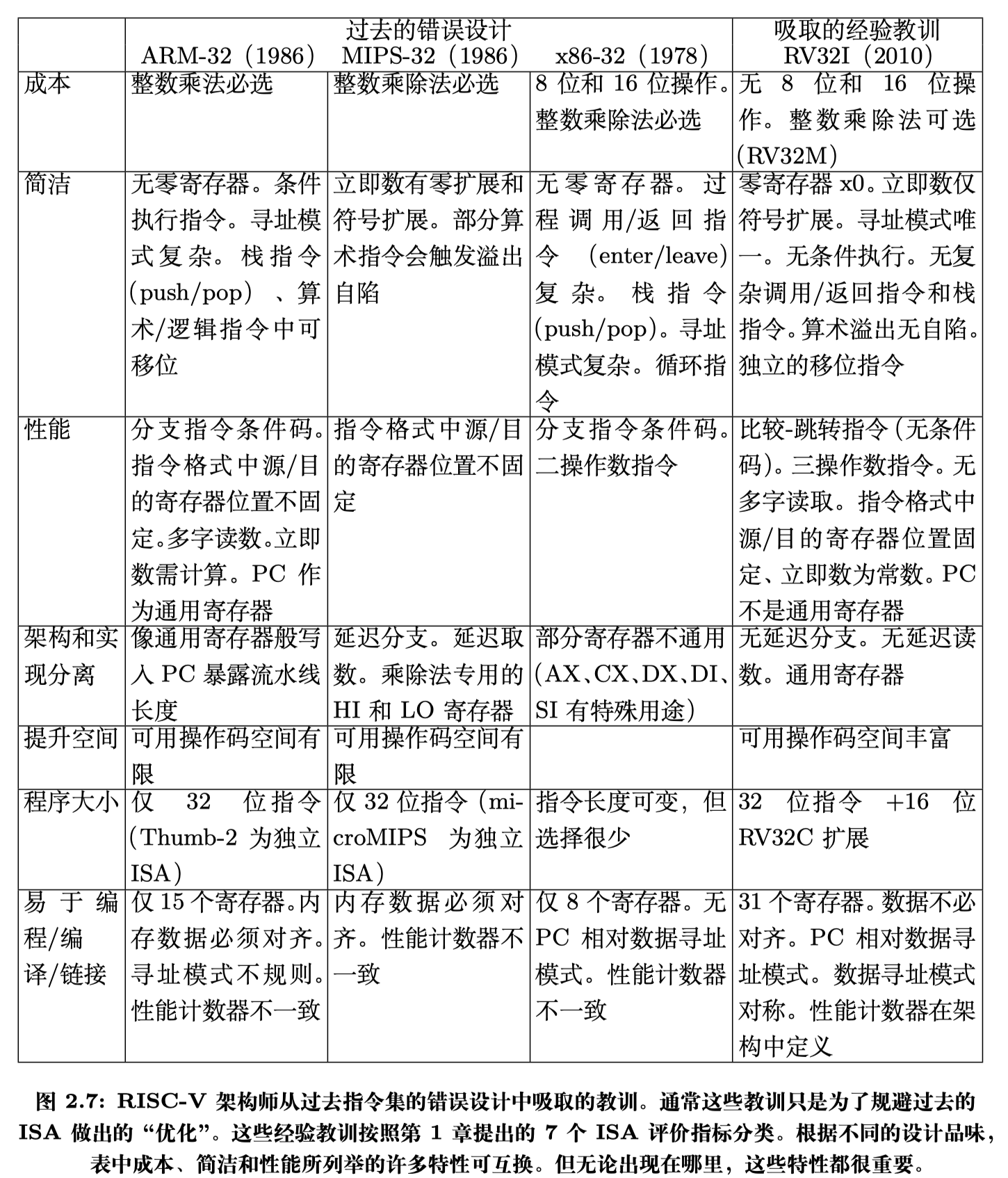
- 易于编程/编译/链接:由于访问寄存器比访问内存快得多,因此编译器必须做好 寄存器分配工作,这在寄存器数量较多时更简单。在这方面,ARM-32 有 16 个寄存 器,而 x86-32 只有 8 个。大多数现代 ISA(包括 RISC-V)都有相对较多的 32 个整 数寄存器。更多寄存器显然能让编译器和汇编语言程序员的工作更轻松。
注:平均时钟周期数可小于 1,因为A9和BOOM[Celio et al. 2015] 是所谓的超标量处理器,每个时钟周期执行多条指令。1.2 RV32I:RISC-V 基础整数指令集
2.1 RV32I指令记忆图
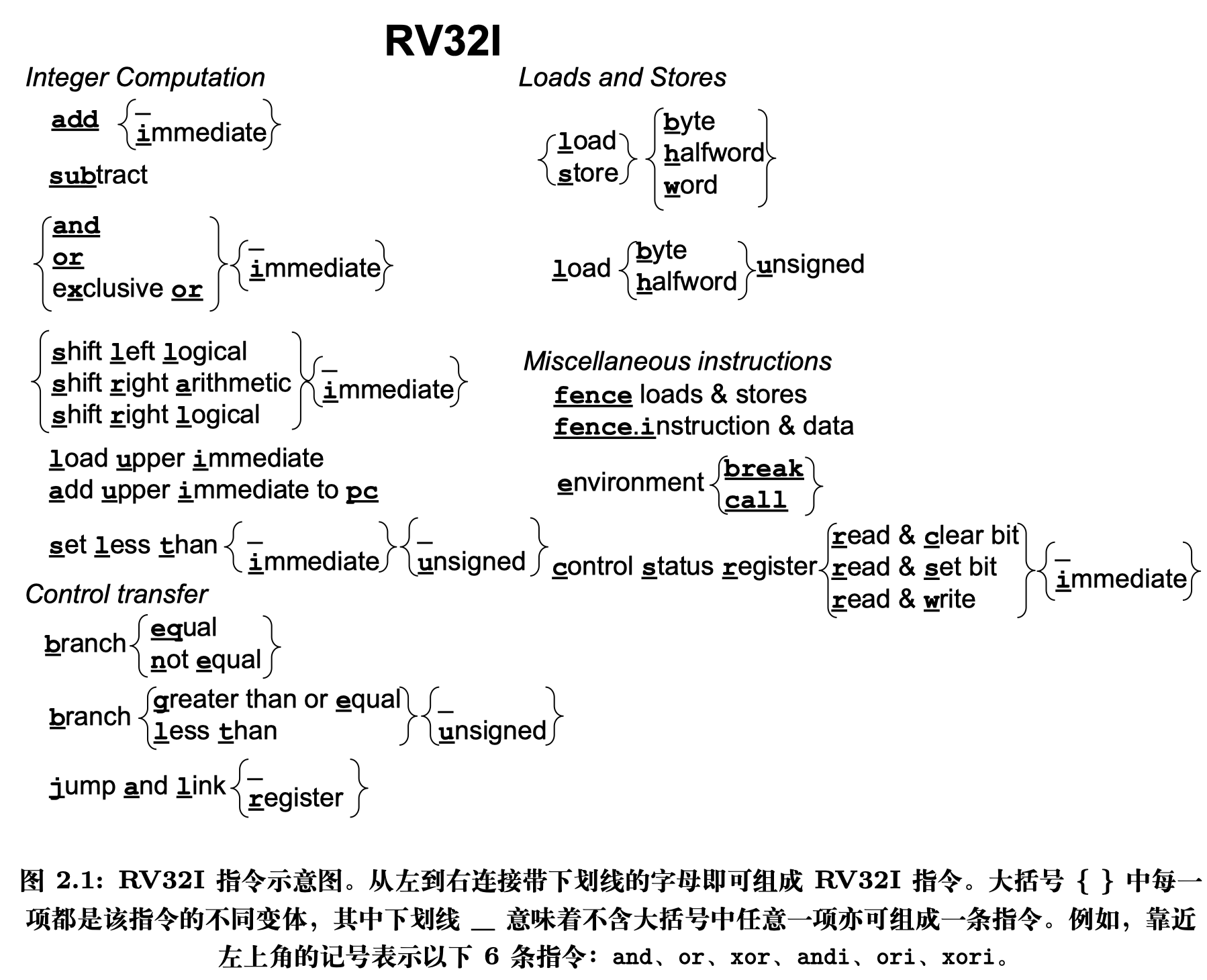
图 2.1 展示了 RV32I 基础指令集,对于图中每组指令,从左到右连接带下划线 的字母,即可组成完整的 RV32I 指令集。大括号 { } 内列举了每组指令的所有变体。 这些变体通过带下划线的字母和不表示任何字母的下划线 _ 区分。

2.2 RV32I 指令格式
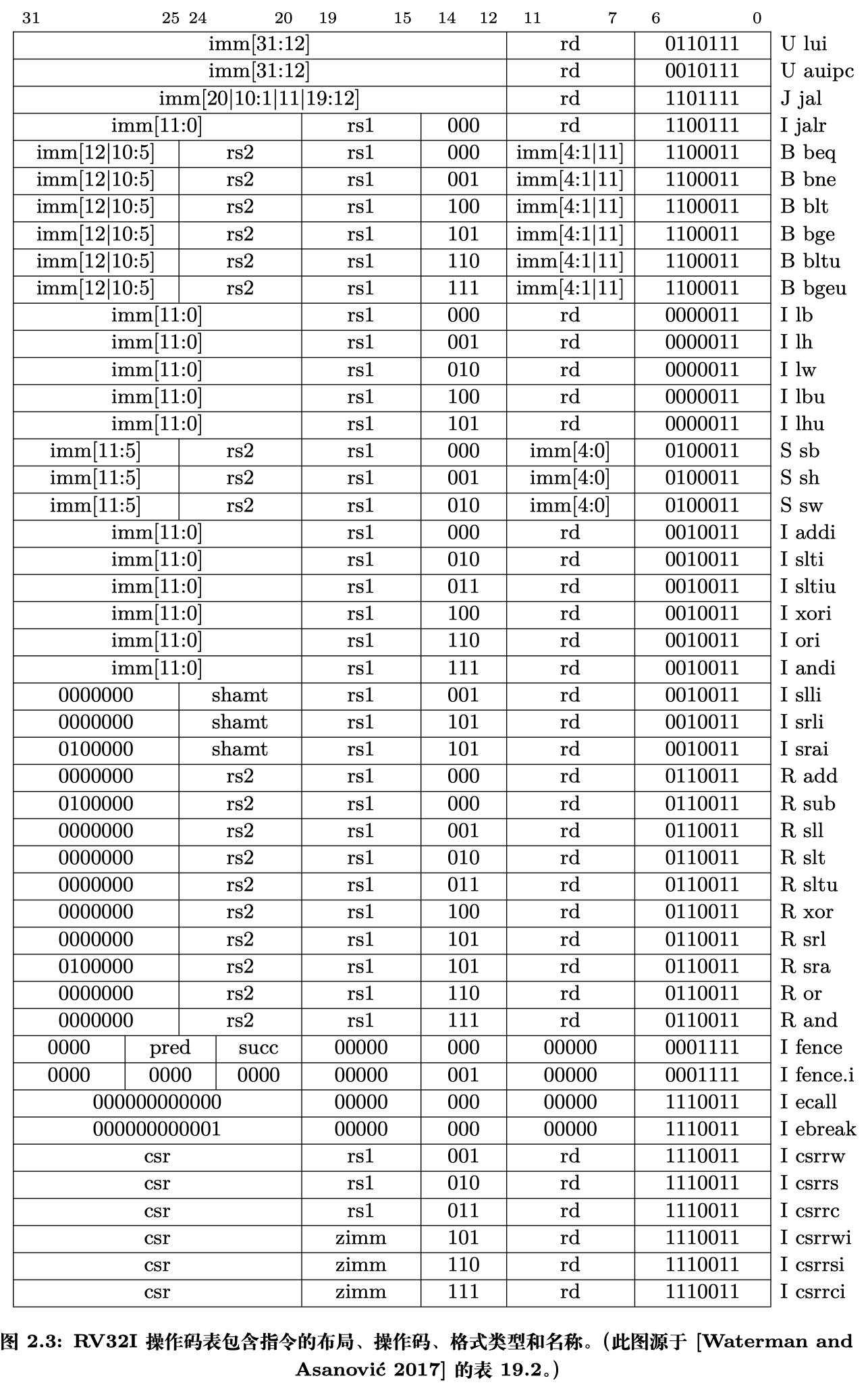
图 2.2 展示了 6 种基本指令格式,分别是:用于寄存器间操作的 R 型,用于短 立即数和取数(load)操作的 I 型,用于存数(store)操作的 S 型,用于条件分支的 B 型,用于长立即数的 U 型和用于无条件跳转的 J 型。图 2.3 按照图 2.2 中指令格 式列出了图 2.1 的所有 RV32I 指令。
注:分支指令的立即数字段在 S 型格式的基础上旋转 1 位,得到 B 型格式。 同样地,跳转指令的立即数字段在 U 型格式的基础上进行旋转,得到 J 型格式 。因 此,RISC-V 实际上只有 4 种基本指令格式,但我们可保守认为有 6 种。
注:立即数格式的设计目标是尽可能使其重叠,从而尽可能减少立即数中每一位的来源,以降低 选择器的成本。例如,imm[5] 可能来源于指令的第 25 位(I 型,S 型,B 型和 J 型)和 0(U 型补零), 因此只需要一个二选一选择器即可选出 imm[5]。但若 J 型立即数采用 imm[20:1] 的立即数格式,imm[5] 将会位于指令的第 16 位,此时需要一个三选一选择器才能选出 imm[5],故增加了选择器成本。


2.3 RV32I 指令特点
作为一款简洁的 ISA,即使从指令格式也能展示使用 RISC-V 提升性价比的若干例子。 首先,RISC-V 只有 6 种指令格式,每条指令都是 32 位,这简化了指令译码 过程。而 ARM-32,尤其是 x86-32,都有大量不同的指令格式,这不仅使低端处理器 的译码开销过大,也给中高端处理器的性能带来挑战。
其次,RISC-V 指令支持 3 个 寄存器操作数,而不像 x86-32 那样,让源操作数和目的操作数共享一个字段。当一个操作本身具有 3 个不同的操作数,而 ISA 的指令只支持两个操作数时,编译器或汇编语言程序员需要额外使用一条传送(move)指令,避免其中一个源操作数被破坏。
再者,在所有 RISC-V 指令中,源寄存器和目的寄存器始终位于同一字段,这意味着可在指令译码前开始访问寄存器。在许多其他 ISA 中,如 ARM-32 和 MIPS-32,某 些字段在一部分指令中作为源操作数,在另一部分指令中又作为目的操作数。为选出 正确的字段,不得不在时序本就紧张的译码路径上额外添加逻辑。
最后,这些指令格 式的立即数字段总是进行符号扩展,其符号位总是位于指令的最高位。此设计方案可 将立即数符号扩展提前到指令译码前进行,从而缓解紧张的时序。

为帮助程序员,所有位全为 0 的指令是一条非法的 RV32I 指令。 因此,错误地 跳转到被清零的内存区域将立即触发自陷,从而帮助调试。类似地,所有位全为 1 的 指令也是非法指令,这能在发生其他常见错误时触发自陷,如访问未编程的非易失性 内存设备、断开连接的内存总线或损坏的内存芯片。
3.1乱序处理器概念
这是一类高速的流水线处理器,它能投机执行指令,而不是严格依据程序的指令顺序 执行。这类处理器的一项关键技术是寄存器重命名,可将程序中的寄存器名映射到大 量的内部物理寄存器。条件执行带来的问题是,无论条件是否成立,都要写入新分配 的物理寄存器。因此条件不成立时,也必须将目的寄存器的旧值作为该指令的第三个 操作数读出,以写入新的目的寄存器。此额外操作数提升了寄存器堆、寄存器重命名 单元和乱序执行硬件的成本。
2.4 RV32I寄存器
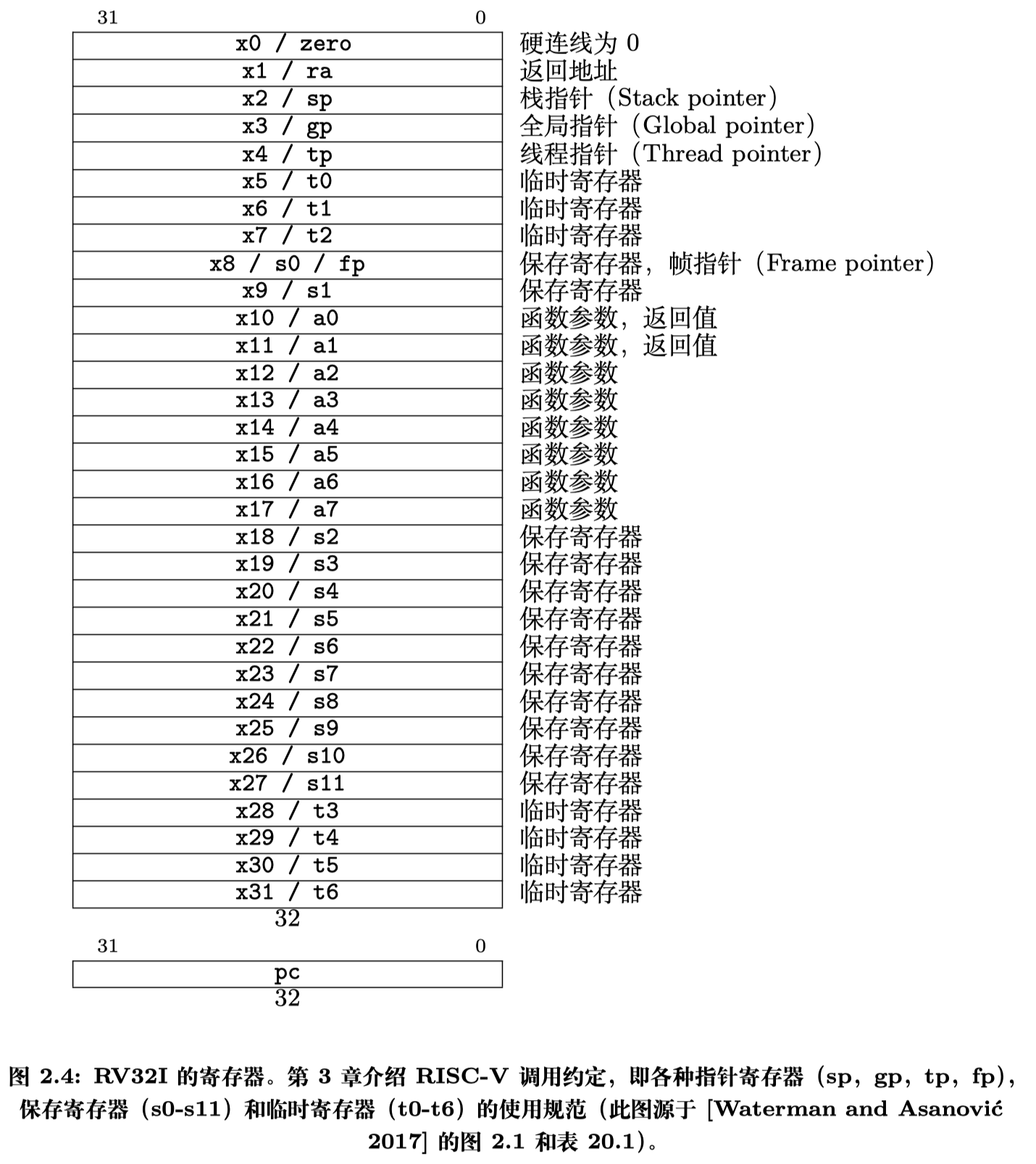
图 2.4 列出了 RV32I 寄存器和由 RISC-V 应用程序二进制接口(Application Binary Interface,ABI)定义的寄存器名称。我们将在示例代码中使用 ABI 名称来提 升可读性。为方便汇编语言程序员和编译器开发者,RV32I 有 31 个寄存器和恒为 0 的 x0 寄存器。相比之下,ARM-32 只有 16 个寄存器,x86-32 甚至只有 8 个。
有何不同? RISC-V ISA 能如此简洁的一个重要原因是,它为常量 0 专门分配一 个寄存器。第 3 章第 35 页图 3.3 列出了许多操作示例,由于 ARM-32 和 x86-32 没 有零寄存器,它们需要通过原生指令实现这些操作。但对于 RISC-V,只需简单地将 零寄存器作为其中一个操作数,即可通过 RV32I 指令实现相同操作。
2.5 RV32I 整数计算
对于图 2.1 的简单算术指令(add、sub)、逻辑运算指令(and、or、xor)和移位指 令(sll、srl、sra),其功能与其他 ISA 类似。它们从源寄存器中读取两个 32 位值, 并将 32 位结果写入目的寄存器。 RV32I 还提供这些指令的立即数版本。和 ARM-32 不同,RV32I 的立即数总是进行符号扩展,因此它们也能表示负数,故 RV32I 中无需 包含立即数版本的 sub 指令。
程序中比较操作的结果是一个布尔值。为支持这种场景,RV32I 提供一条小于则 置位(set less than)指令。若第一个操作数小于第二个操作数,则将目的寄存器设为 1,否则设为 0。该指令包括有符号版本(slt)和无符号版本(sltu),分别用于有符号和无符号整数的比较,同时也有相应的立即数版本(slti、sltiu)。虽然 RV32I 分支指令支持两个寄存器间的所有关系运算,但条件表达式可能涉及多对寄存器间的关系,此时编译器或汇编语言程序员可将 slt 和 and、or、xor 等逻辑运算指令组合, 以处理更复杂的条件表达式。
图 2.1 中剩下的两条整数计算指令有助于汇编和链接。装入高位立即数(lui)将 20 位立即数装入寄存器的高 20 位,可与后续一条 RV32I 立即数指令共同构造出 32 位常数。PC 加高位立即数(auipc)使得仅需 2 条指令即可实现任意偏移的 PC 相对控制流转移和数据访问。具体地,将 auipc 与 jalr(见下文)中 12 位立即数组合,可将控制流转移到任意 32 位 PC 相对地址;而 auipc 加上访存指令的 12 位立 即数偏移量,可访问任意 32 位 PC 相对地址的数据。(这段话的ai解释在下面)
有何不同? 首先,RV32I 中没有字节或半字的整数计算操作,所有操作的位宽均与寄存器位宽相同。 内存访问的能耗比算术运算高几个数量级, 因此短数据访存可大幅降低能耗,但短数据运算不会。此外,ARM-32 可在大多数算术和逻辑操作中对 其中一个操作数进行移位,此特殊功能使数据通路更复杂,但很少使用。与之相对, RV32I 提供独立的移位指令。
乘法和除法不在 RV32I 中,相反,它们组成可选的 RV32M 扩展(见第 4 章)。 与 ARM-32 和 x86-32 不同,即使处理器未实现乘除法,也能运行完整的 RISC-V 软 件栈,这能减小嵌入式芯片的面积。MIPS-32 汇编器可能用一系列移位和加法指令代 替乘法来提高性能,但这会让处理器执行一些汇编语言程序中不存在的指令,令程序 员感到困惑。RV32I 不支持循环移位指令和整数算术溢出检测,但它们均可通过少数 几条 RV32I 指令实现(见第 2.7 节)。
3.1 使用xor交换寄存器
可以使用xor操作来交换两个寄存器,但这种方式要运行三条指令,如果有一个中间寄存器就只要运行两条指令,通常寄存器数量都是足够的,所以这种方式很少用

3.2 AI解释

2.6 RV32I 取数和存数
如图 2.1 所示,除了 32 位字的取数和存数指令(lw、sw)外,RV32I 还支持有符 号和无符号的字节和半字取数指令(lb、lbu、lh、lhu),以及字节和半字的存数指令 (sb、sh)。对于有符号的字节和半字数据,指令先将其符号扩展为 32 位,再写入目 的寄存器,使后续整数计算指令可正确处理 32 位数据。而对于常用于文本和无符号 整数的无符号字节和半字数据,指令先将其零扩展为 32 位,再写入目的寄存器。
访存指令唯一支持的寻址模式是将 12 位立即数符号扩展后与寄存器相加,这在 x86-32 中称为偏移寻址 [Irvine 2014]。
有何不同? RV32I 未采用 ARM-32 和 x86-32 的复杂寻址模式。RV32I 的所有寻 址模式均适用于所有数据类型,但 ARM-32 并非如此。RISC-V 能模拟 x86 的部分寻址模式,例如,将立即数字段设为 0 即可实现寄存器间接寻址的效果。与 x86-32 不 同,RISC-V 没有专用的栈指令,通过将一个通用寄存器作为栈指针(见图 2.4),即 可使标准寻址模式具备压栈(push)和弹栈(pop)指令的大部分优点,而无需增加 ISA 复杂性。与 MIPS-32 不同,RISC-V 不支持延迟取数(delayed load)。与延迟分 支的思想类似,为配合 5 级流水线,MIPS-32 重新定义取数指令的行为,读取的数据 在两条指令后才能使用。但对于后来出现的长流水线,此设计并无好处。
ARM-32 和 MIPS-32 要求内存中的数据按其长度对齐,而 RISC-V 无此要求。 移植旧代码有时需要不对齐访存的支持。一种方案是在基础 ISA 中禁止不对齐访存, 同时提供专用指令来支持,如 MIPS-32 的读左侧字(Load Word Left,lwl)和读右侧字(Load Word Right,lwr)。 但这两条指令只写入寄存器的一部分,使寄存器访 问复杂化。另一种方案是让普通访存指令支持不对齐访存,从而简化整体设计。

注:不对齐访存的含义


3.1字节序



2.7 RV32I 条件分支
RV32I 可比较两个寄存器,并根据比较结果是否相等(beq)、不相等(bne)、大 于等于(bge)或小于(blt),决定是否跳转。后两种为有符号比较,RV32I 也提供 相应的无符号版本:bgeu 和 bltu。剩余两种比较操作(大于和小于等于)可简单通 过交换操作数实现,如 y > x 等价于 x < y,y ≤ x 等价于 x ≥ y。
注: 可借助一条 bltu 指令检查有符号的数组边界,因为根据无符号比较,负索引比任意非负边界值都大!


由于 RISC-V 指令长度必须是两字节的倍数(可选的两字节指令参见第 7 章), 分支指令的寻址方式将 12 位立即数乘以 2,符号扩展后与 PC 相加。 PC 相对寻址 有助于实现位置无关代码,以简化链接器和加载器的工作(见第 3 章)
有何不同? 如前文所述,RISC-V 不支持 MIPS-32、Oracle SPARC 等指令集中 被广为诟病的延迟分支特性,也不像 ARM-32 和 x86-32 那样使用条件码实现条件分支。条件码的存在使大多数指令必须隐式设置若干额外状态,使乱序执行的依赖关系 判断变得更复杂。 最后,RISC-V 不支持 x86-32 的循环指令,包括 loop、loope、 loopz、loopne、loopnz。
3.1 无需条件码的多字加法

3.2 获取PC

3.3 软件检查溢出

2.8 RV32I 无条件跳转
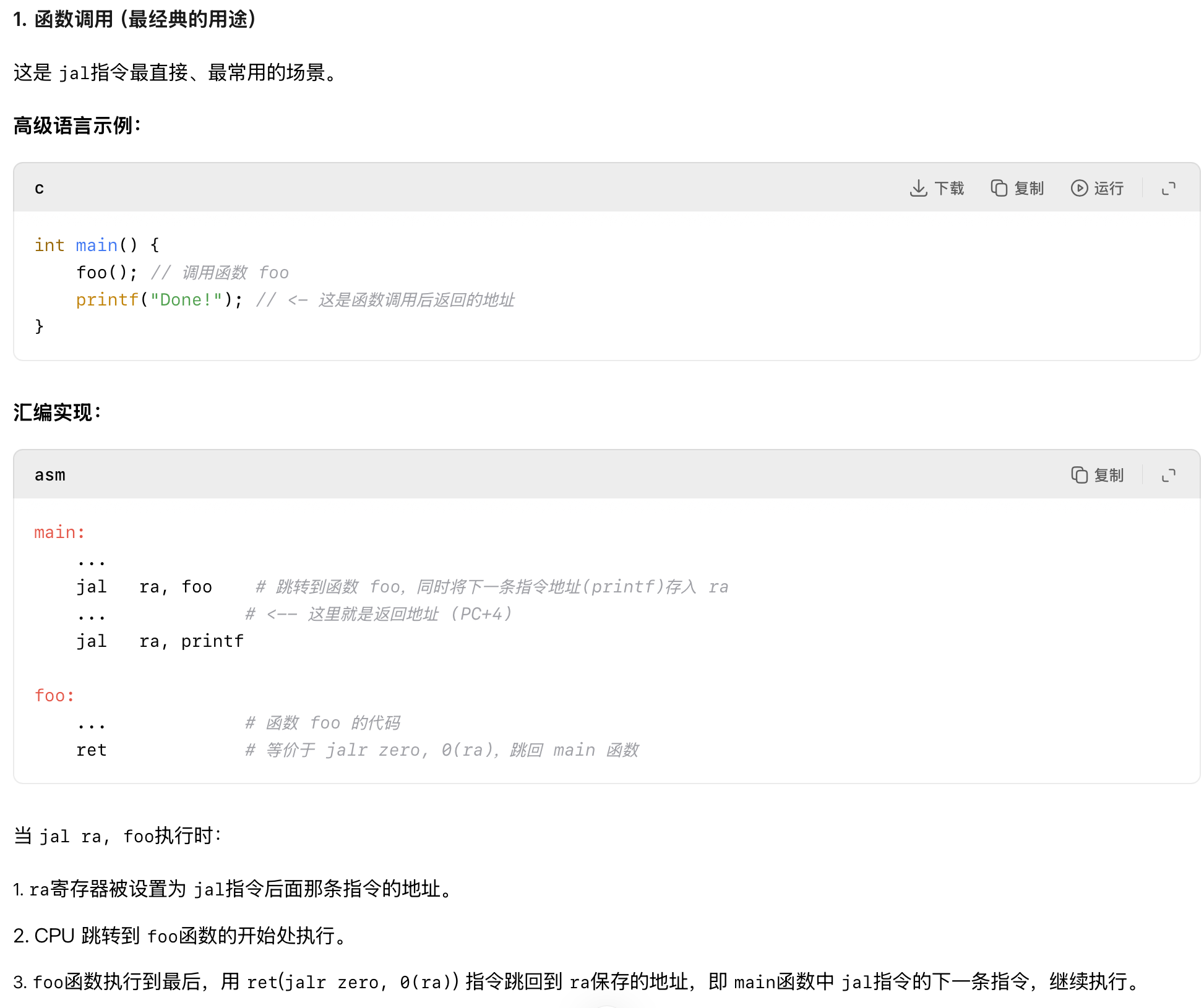
图 2.1 的跳转并链接(jal)指令具有两种功能。为支持过程调用,它将下一条指令的地址(PC+4)保存到目的寄存器中,通常保存到返回地址寄存器 ra(图 2.4)。 为支持无条件跳转,可将目的寄存器从 ra 换成零寄存器(x0),因为写入 x0 不改变 其值。和分支指令类似,jal 将 20 位立即数乘以 2,符号扩展后与 PC 相加,从而得 到跳转目标地址。
跳转并链接指令的寄存器版本(jalr)同样有多种用途。它能调用那些地址需要动态计算的过程,也能将 ra 和 x0 分别作为源寄存器和目的寄存器,实现从过程中返回。将 x0 作为目的寄存器,则能实现需要计算跳转地址的 switch 和 case 语句。
有何不同? RV32I 不支持复杂的过程调用指令,如 x86-32 的 enter 和 leave 指令,也没有引入 Intel 的 Itanium,Oracle 的 SPARC 和 Cadence 的 Tensilica 中的 寄存器窗口(register window)特性。
注:寄存器窗口技术通过远多于 32 个寄存器来加速函数调用。函数调用时,处理器会为其分配新的一组 32 个寄存器(也称为窗口)。为支持参数传递,两个函数的窗口会重叠,这意味着部分寄存器同时属于两个相邻窗口。
2.9 其他RV32I指令

2.10 通过插入排序对比 RV32I、ARM-32、MIPS-32 和 x86-32
3.1测试对比
我们介绍了 RISC-V 基础指令集,并与 ARM-32,MIPS-32 和 x86-32 对比说明 其设计选择。下面通过真实程序进行量化对比。图 2.5 是插入排序的 C 语言实现,我 们把它作为对比的基准测试,将其编译到不同 ISA 的指令数和字节数如图 2.6 所示。



3.2汇编代码分析
图 2.8 至 2.11 展示了编译插入排序生成的 RV32I、ARM-32、MIPS-32 和 x86-32 汇编代码。尽管 RISC-V 强调简洁性,但所用指令数与其他 ISA 相同甚至更少,代码大小也十分相近。 本例中,RISC-V 采用比较-执行分支指令所节省的指令数,与 ARM-32(图 2.9)和 x86-32(图 2.11)采用复杂寻址模式以及压栈/弹栈指令所节省的指令数相当。
jalr指令作用解析在下面




3.3 jalr、jal指令解析
jalr可以用于调用函数和退出函数
jal可以用于调用函数
jalr解析


jal解析


Comments NOTHING