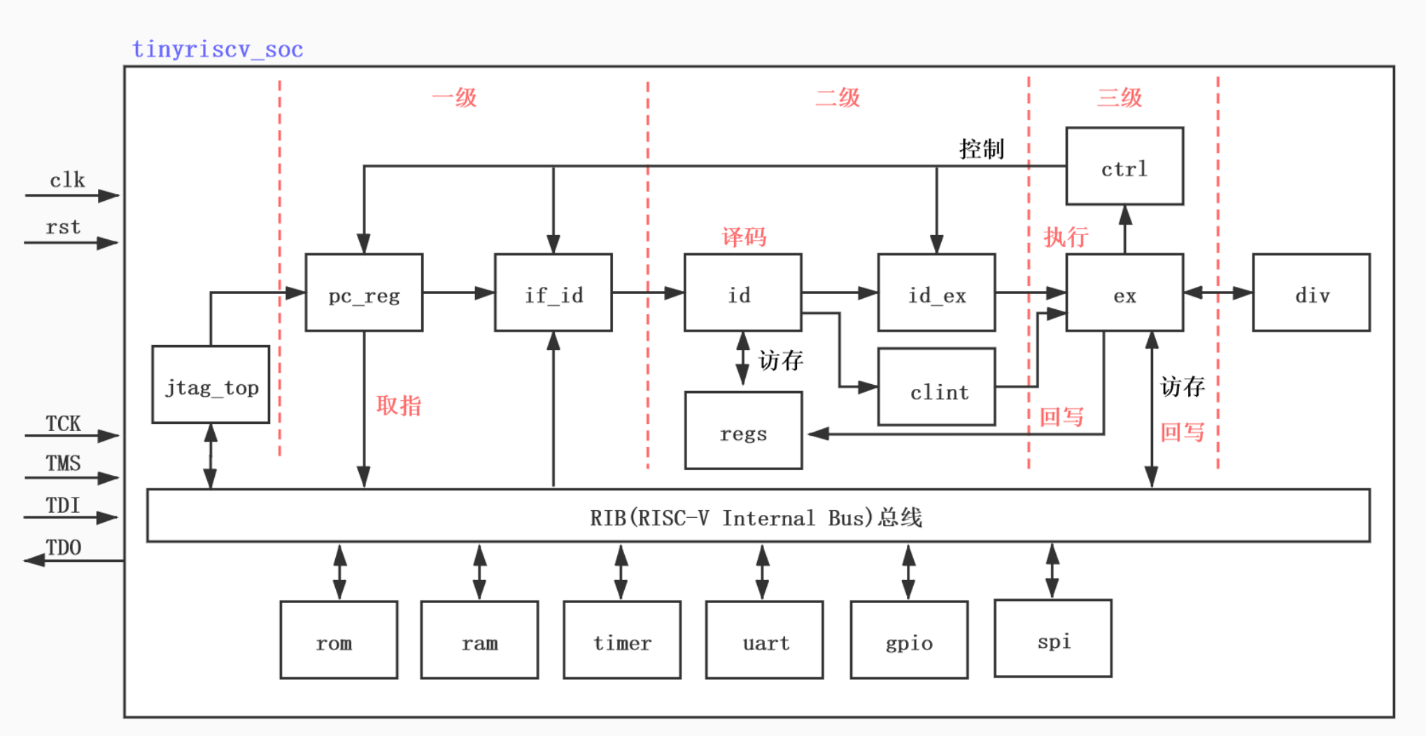
近期学习了一个riscv指令集soc工程(tinyriscv),对riscv的指令集和系统基本架构有了初步的学习了解,其基本框架图如下
老师建议用DC给该工程跑一遍综合,我花了几天时间学习,整理出一篇学习笔记,也算是一个小入门吧
reference:
DC report_timing 报告分析(STA)
DC入门篇——read和analyze&elaborate的区别
DC综合入门篇——脚本操作
Linux环境下EDA软件的使用——数字IC设计DC综合篇
IC学习 | Design Compiler综合学习总结(二)
Design Compiler入门
NangateOpenCellLibrary-45nm
tinyriscv
目录
- DC综合概述
- 基础学习
- 准备工作
- 命令行模式常用命令
- 命令行运行DC工具
- DC综合实践
- 创建项目目录结构
- 选取工艺库
- 编写并运行综合脚本
- 两种工艺综合后结果对比分析
- timing_report
- area_report
- power_report
- 原理图对比
- cpu利用率
- Debug
- 总结
DC综合概述
逻辑综合分为三个阶段:
-
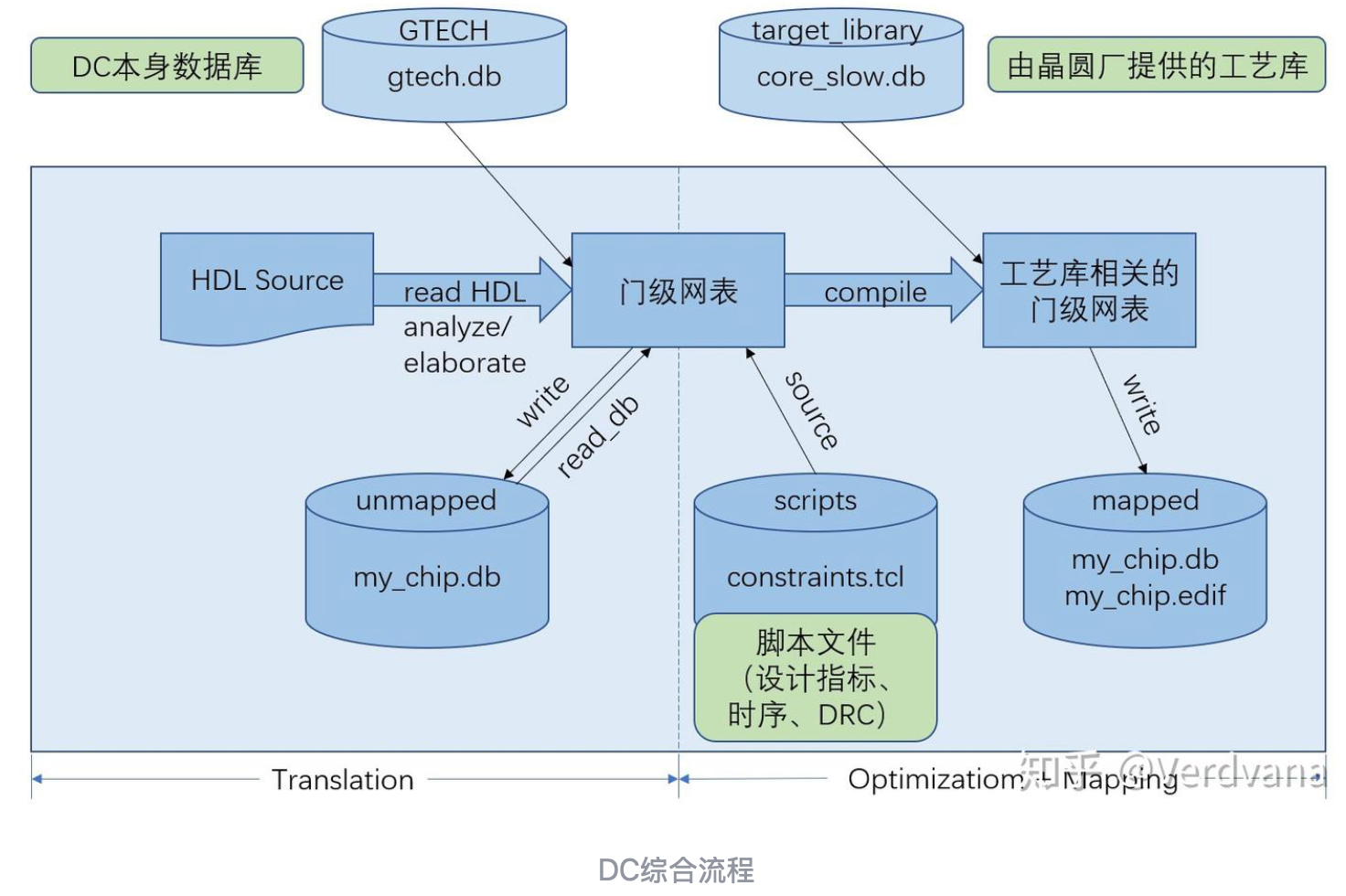
转译(Translation):把电路转换为EDA内部数据库,这个数据库跟工艺库是独立无关的;
-
优化(Optimozation):根据工作频率、面积、功耗来对电路优化,来推断出满足设计指标要求的门级网表;
-
映射(Mapping):将门级网表映射到晶圆厂给定的工艺库上,最终形成该工艺库对应的门级网表。
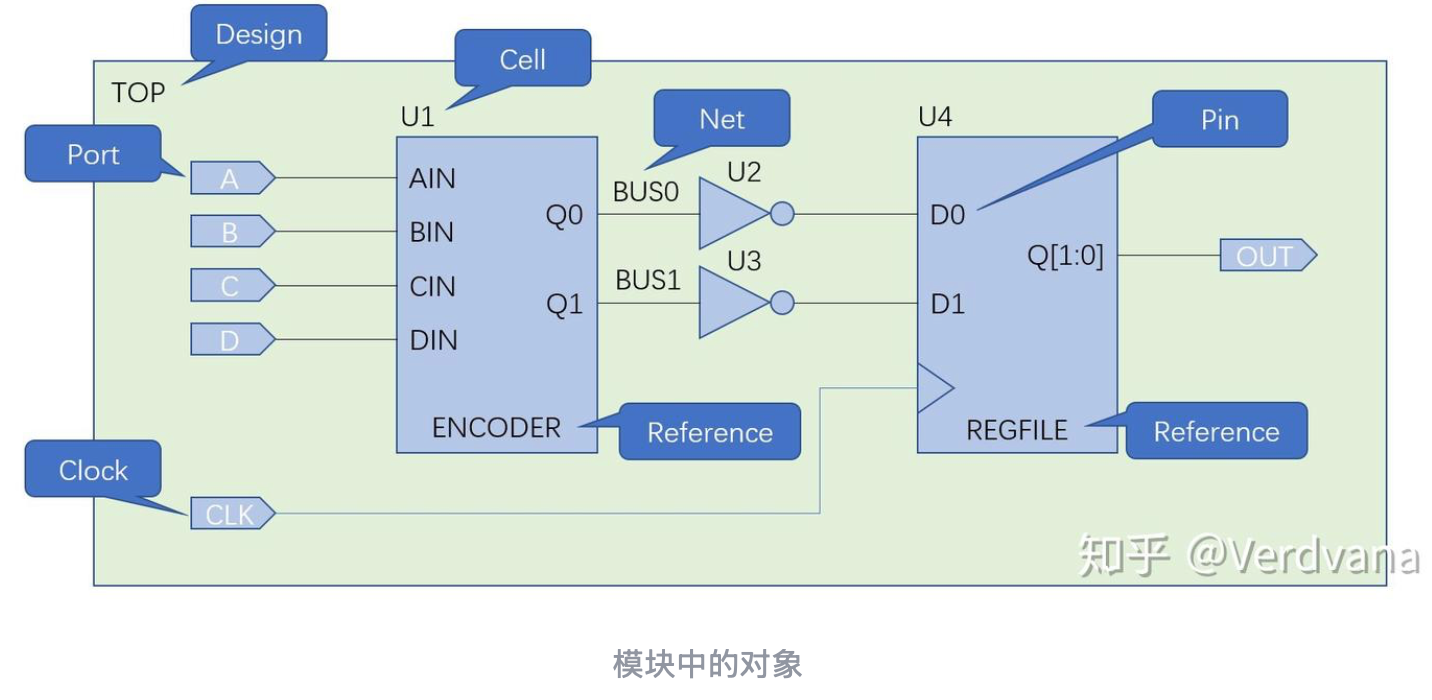
DC在综合过程中会把电路划分为以下处理对象: -
Design:待综合的对象(module);
-
Port:Design最外部的端口;
-
Clock:时钟;
-
Cell:被例化的模块;
-
Reference:例化的原电路。

DC综合的流程如下图所示

使用DC逻辑综合的流程大致可以分为以下几个部分: -
预综合过程(Pre-Synthesis Processes):在综合过程之前的一些为综合做准备的步骤:
- DC启动;
- 设置各种库文件:
- link_library;
- target_library;
- symbol_library;
- 创建启动脚本文件;
- 读入设计文件;
- analyze;
- elaborate;
- read_file;
- DC中的设计对象;
- 各种模块划分;
- Verilog的编码。
-
施加设计约束:
- 设置环境约束:
- set_operating_coditions;
- set_wire_load;
- set_drive;
- set_driving_cell;
- set_load;
- set_fanout_load;
- 设置时序约束:
- 设计规则的约束:
- set_max_transition;
- set_max_fanout;
- set_max_capacitance;
- 优化的约束:
- create_clock;
- set_clock_skew;
- set_input_delay;
- set_output_delay;
- set_max_area;
- 设计规则的约束:
- 设置环境约束:
-
设计综合;
-
后综合。
基础学习
准备工作
所需文件:
- RTL设计文件(.v 或 .vhdl)
- 工艺库文件(.db,如
tsmc28nm.db) - 约束文件(.sdc,可选)
启动DC:
dc_shell # 命令行模式(推荐) 或
design_vision # 启动图形界面gui界面打开如下
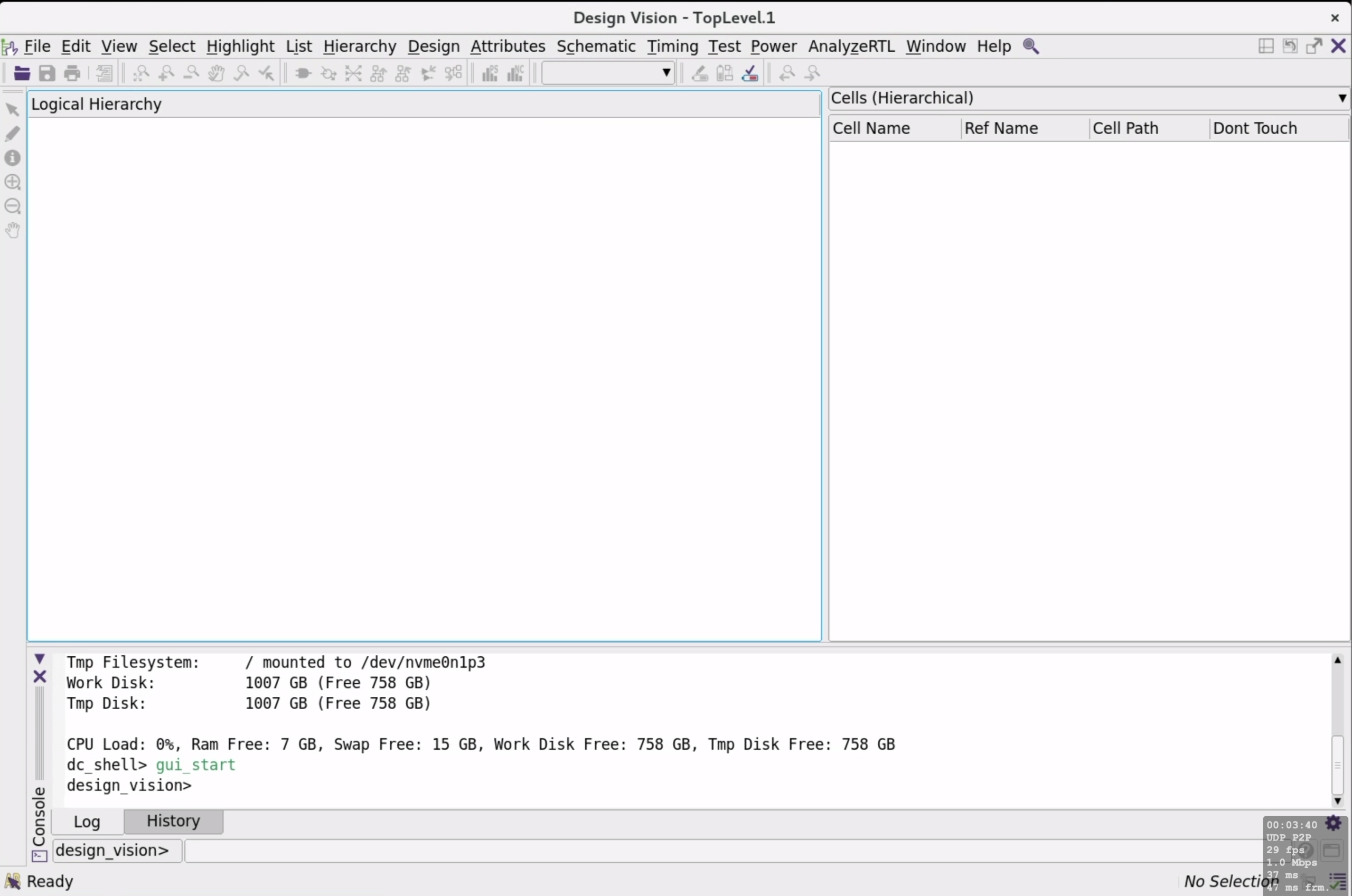
可以看到,界面整体的结构比较清晰,包括上方的菜单栏,中间部分左边是综合后的逻辑层次窗口,右边可以查看代码的层次结构,下方是log输出和指令输入窗口
命令行模式常用命令
指定工艺库文件
#-------------------Specify Libraries------------------
set search_path { . /LM}
set link_library { */LM/tcbn45gsbwpwc.db }
set target_library { /LM/tcbn45gsbwpwc.db }注意:在 link_library 的设置中必须包含" “,” “表示 DC 在引用实例化模块 或者单元电路时首先搜索已经调进DC memory的模块和单元电路,如果在link library 中不包含” * ",DC 就不会使用 DC memory 中已有的模块,因此,会出现无法匹配的模块或单元电路的警告信息(unresolved design reference)。
读取设计文件
DC读入设计文件有两种方式,一是read指令,二是 analyze 和 elaborate 的组合
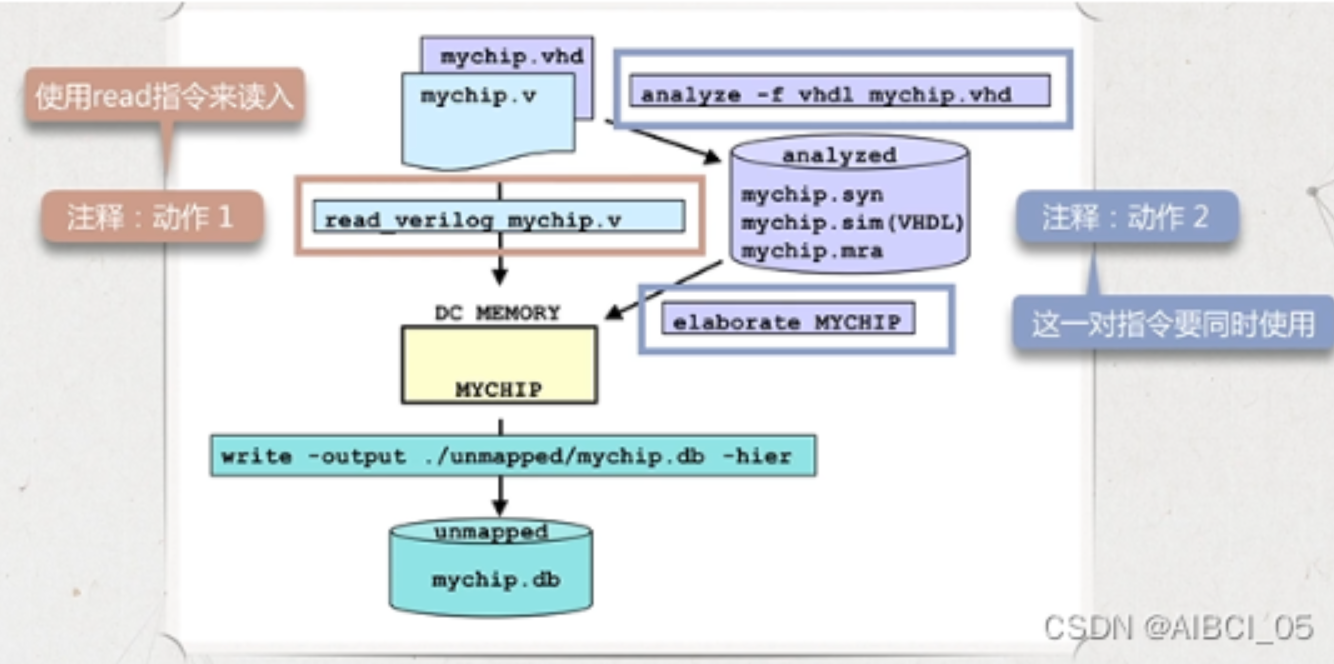
如果读入单个文件可以使用指令。
read_verilog alu.v如果需要读入多个文件可以使用如下函数。
# 设置verilog文件所在的目录rtl
set design_path "rtl"
set verilog_files [glob -nocomplain -type f $design_path/*.v]
foreach file $verilog_files {
read_file -format verilog $file
}当读取完所有要综合的模块之后,需要使用link命令将读取到 DC 存储区的模块或者实例连接起来。同时由于DC默认将最后读入的一个模块作为顶层模块。因此在Link之前还需要利用current_design指令指定顶层模块。
# 设置顶层模块的名字
set top_name alu
current_design $top_name
link
uniquify注意:对于被多次实例化的同一子设计,由于其例化后的工作环境各不相同,因此,需要用 uniquify 命令为每个实例在内存中创建一份副本,以便区分开每个实例。DC可以根据不同的应用环境进行合适的优化。
注意:对于带有参数的工程,需要使用另一种方式导入文件,详见Debug_bug3
时钟约束
指令create_clock对clk端口进行时钟约束,周期period为10ns(100MHz),waveform设置占空比。
create_clock -name clk -period 10 -waveform { 0 5 } [get_ports clk]如果对组合逻辑电路进行时钟约束,使用下列命令会生成虚拟时钟,用于时序分析。
create_clock -name clk -period 10 -waveform {0 5}注意:由于时钟信号是驱动大负载的。在综合的时候综合工具会对负载进行估 计,从而在该网络上加上一些有足够驱动能力的 buffer 或者反相器,以使得电路的上升时间和下降时间能够满足要求。而前端工具无法知道连线的走向和长度,在估计时钟网络的负载时不准确,而且 floorplan 的结果将会 影响连线的长度,从而影响连线的负载,因此,前端工具不对大负载的网络进行处理,而把这个工作留到后端。所以在综合的时候需要告诉综合工具不对时钟网络进行处理。
#为了防止在时钟路径上插入Buffer而恶化时序,所以对时钟网络设置Dont_touch_network属性,即综合的时候不对Clk信号行优化
set dont_touch_network [get_clocks clk]输入输出约束
set_input_delay 1.5 -clock CLK [get_ports data_in]
set_output_delay 2.0 -clock CLK [get_ports data_out]
# 所有输出port的输出负载电容设置为10pf set_load 0.01 [all_output]
set_load 0.01 [all_output]指定线程数
set_host_options -max_cores 8 ;# 使用8核CPU综合设计
使用compile或者compile_ultra进行综合。compie_ultra命令包括许多高级的综合优化算法,可以使关键路径的分析和优化在最短时间内完成。但是需要额外的licence。
# 保持默认优化条件进行编译
compile
# 或者compile_ultra查看报告并分析
利用以下命令保持面积、功耗、时序、约束违例和summary报告在report文件夹中。
#-------------------Generate Reports-------------------
report_area > ./report/area_report.txt
report_power > ./report/power_report.txt
report_timing > ./report/timing_report.txt
# all_violators指的是所有没有达到要求的约束
report_constraint -all_violators > ./report/violators.txt
report_qor > ./report/qor_report.txt 综合输出文件保存
ddc文件:保留综合结果的ddc文件,可以直接load这个文件,查看综合结果;
sdc(Synopsys design constraints.)文件:保留了本次设计时序约束信息;
sdf(Standard Delay Format)文件:标准延时格式,用于静态分析和后仿;
netlist.v文件:综合后吐出的门级网表。
#-------------------Save Output File-------------------
write_sdc ./output/top.sdc
write_sdf -version 2.1 ./output/top.sdf
write -f verilog -hier -output ./output/netlist.v
write_file -f ddc -hierarchy -output ./output/top.ddc命令行运行
在目录下打开终端运行以下命令即可。运行的日志保存在run.log中方便查看和Debug。
#在dc_shell内运行脚本
dc_shell
source -e -v run.tcl > run.log
#直接运行并打印
dc_shell -f run.tcl | tee run.log
#后台运行
nohup dc_shell -f run.tcl > run.log
#后台运行且不因ssh中断而挂断程序
#使用tmux命令
tmux
nohup dc_shell -f run.tcl > run.log
exit
#终止程序运行
#查看运行的dc_shell的ID
ps aux | grep dc_shell
kill IDDC综合实践
选取入门开源soc tinyriscv
地址: https://gitee.com/liangkangnan/tinyriscv
tinyriscv工程源码结构如下
rtl
├── core #riscv内核
│ ├── clint.v
│ ├── csr_reg.v
│ ├── ctrl.v
│ ├── defines.v #参数宏定义文件
│ ├── div.v
│ ├── ex.v
│ ├── id_ex.v
│ ├── id.v
│ ├── if_id.v
│ ├── pc_reg.v
│ ├── regs.v
│ ├── rib.v #总线
│ └── tinyriscv.v
├── debug #jtag
│ ├── jtag_dm.v
│ ├── jtag_driver.v
│ ├── jtag_top.v
│ └── uart_debug.v
├── perips #外设(包括rom和ram)
│ ├── gpio.v
│ ├── ram.v
│ ├── rom.v
│ ├── spi.v
│ ├── timer.v
│ └── uart.v
├── soc #顶层模块互联(soc)
│ └── tinyriscv_soc_top.v
└── utils #其他复用小模块
├── full_handshake_rx.v
├── full_handshake_tx.v
├── gen_buf.v
└── gen_dff.v创建项目目录结构
mkdir -p DC_prj/{rtl,scripts,reports,outputs,libs}
cp -r usr/src/rtl/* DC_prj/rtl/ # 复制RTL代码
cd DC_prj选取工艺库(class和NangateOpenCellLibrary)
分别使用了两个工艺库:
class.db:DC软件自带的虚拟工艺库
NangateOpenCellLibrary:45nm开源工艺库
地址: https://github.com/mflowgen/freepdk-45nm/tree/master
编写并运行综合脚本
创建 run.tcl 文件 mkdir run.tcl:
#输出时间和清除原本的设计
sh date
remove_design -designs
#------------------------Define------------------------
set top_name tinyriscv_soc_top
#-------------------Specify Libraries------------------
set search_path "./libs"
#class.db
#stdcells.db
set target_library "./libs/stdcells.db"
set link_library "* $target_library"
#----------------------Read Designs--------------------
# set_dont_touch [find cell -hierarchy *ram*] ;# 不优化RAM
# set_dont_touch [find cell -hierarchy *rom*] ;# 不优化ROM
# 运行过程会产生很多中间文件,修改中间文件的存储位置
set work_path work
define_design_lib work -path $work_path
# 遍历查找根目录下所有的 Verilog 文件
set source_file [sh find ./rtl -name "*.v"]
analyze -format verilog -lib work $source_file
elaborate $top_name
## Reset all constraints
# reset_design
uniquify
#-------------------Operating environment--------------
set_load 0.01 [all_output]
#--------------------Design Constrains-----------------
create_clock -name clk -period 20 -waveform {0 10} [get_ports clk]
set_max_area 0
#---------------------Run Compile----------------------
set_host_options -max_cores 32 ;# 使用32个CPU核心
compile_ultra
#-------------------Generate Reports-------------------
report_area > ./reports/area_report.txt
report_power > ./reports/power_report.txt
report_timing > ./reports/timing_report.txt
report_constraint -all_violators > ./reports/violators.txt
report_qor > ./reports/qor_report.txt
#-------------------Save Output File-------------------
write_sdc ./outputs/top.sdc
write_sdf -version 2.1 ./outputs/top.sdf
write -f verilog -hier -output ./outputs/netlist.v
write_file -f ddc -hierarchy -output ./outputs/top.ddc
exit终端运行代码
#在dc_shell内运行脚本
dc_shell
source -e -v run.tcl > run.log
#直接运行并打印
dc_shell -f run.tcl | tee run.log
#后台运行
nohup dc_shell -f run.tcl > run.log
#后台运行且不因ssh中断而挂断程序
#使用tmux命令
tmux
nohup dc_shell -f run.tcl > run.log
exit
#终止程序运行
#查看运行的dc_shell的ID
ps aux | grep dc_shell
kill ID两种工艺综合结果对比分析
timing_report
报告开始显示了路径的起点,路径终点,路径组名和路径检测的类型。此例中,路径检测类型为max,意味着最大的延时或者setup check,若是min则是最小的延时或者hold check
下面一个大表显示了从起点到终点之间的一个个点的延时值。纵列有三个标识, Point, Incr和 Path,分别表示了路径中的各个点,此点所需要的延时和从起点一直累积到此点的延时值。(一般是6列:point、fanout扇出值、trans传输延时、incr器件延时、path、attributes延时类型)
路径由数据载入的时钟沿开始,到device的数据输入端结束。表中的data arrival time表示了从载入时钟沿到终点数据到达所经历的时间
再用required time减去arrival time 则得到了slack值
class虚拟工艺库时序报告如下,时序裕度为负值-12.11,可见class工艺库的工艺水平无法满足tinyriscv的时序需求(其可在xilinx中xc7a35t FPGA中以50M时钟运行),若使用class工艺库,需要继续优化工程的时序
Startpoint: u_tinyriscv/u_id_ex/inst_ff/qout_r_reg[2]
(rising edge-triggered flip-flop clocked by clk)
Endpoint: u_tinyriscv/u_regs/regs_reg[25][27]
(rising edge-triggered flip-flop clocked by clk)
Path Group: clk
Path Type: max
Des/Clust/Port Wire Load Model Library
------------------------------------------------
tinyriscv_soc_top 20x20 class
Point Incr Path
--------------------------------------------------------------------------
clock clk (rise edge) 0.00 0.00
clock network delay (ideal) 0.00 0.00
u_tinyriscv/u_id_ex/inst_ff/qout_r_reg[2]/CP (FD1) 0.00 # 0.00 r
u_tinyriscv/u_id_ex/inst_ff/qout_r_reg[2]/Q (FD1) 1.63 1.63 f
U12174/Z (NR2I) 0.89 2.52 r
U11857/Z (ND2I) 0.25 2.77 f
......
U21503/Z (ND2I) 1.22 30.82 f
U21590/Z (MUX21L) 0.48 31.31 r
u_tinyriscv/u_regs/regs_reg[25][27]/D (FD1) 0.00 31.31 r
data arrival time 31.31
clock clk (rise edge) 20.00 20.00
clock network delay (ideal) 0.00 20.00
u_tinyriscv/u_regs/regs_reg[25][27]/CP (FD1) 0.00 20.00 r
library setup time -0.80 19.20
data required time 19.20
--------------------------------------------------------------------------
data required time 19.20
data arrival time -31.31
--------------------------------------------------------------------------
slack (VIOLATED) -12.11NangateOpenCellLibrary 45nm开源工艺库时序报告如下,仍然保留了很大的时序裕度12.22,可以推测class虚拟工艺库是一个较落后的工艺,也说明了工艺的进步对时序的影响非常大,有了更好的工艺,处理器才可以运行在更高的频率下
Des/Clust/Port Wire Load Model Library
------------------------------------------------
tinyriscv_soc_top 5K_hvratio_1_1 NangateOpenCellLibrary
Point Incr Path
--------------------------------------------------------------------------
clock clk (rise edge) 0.00 0.00
clock network delay (ideal) 0.00 0.00
u_tinyriscv/u_id_ex/op2_ff/qout_r_reg[1]/CK (DFF_X1)
0.00 # 0.00 r
u_tinyriscv/u_id_ex/op2_ff/qout_r_reg[1]/Q (DFF_X1) 0.20 0.20 r
u_tinyriscv/u_ex/op2_i[1] (ex) 0.00 0.20 r
u_tinyriscv/u_ex/U42/ZN (INV_X2) 0.14 0.34 f
......
u_ram/U180785/ZN (OAI22_X1) 0.11 7.71 r
u_ram/U180786/ZN (INV_X1) 0.02 7.73 f
u_ram/_ram_reg[1856][24]/D (DFF_X1) 0.01 7.74 f
data arrival time 7.74
clock clk (rise edge) 20.00 20.00
clock network delay (ideal) 0.00 20.00
u_ram/_ram_reg[1856][24]/CK (DFF_X1) 0.00 20.00 r
library setup time -0.04 19.96
data required time 19.96
--------------------------------------------------------------------------
data required time 19.96
data arrival time -7.74
--------------------------------------------------------------------------
slack (MET) 12.22area_report
各项指标含义
| 参数 | 含义 | 面积类型 | 含义 |
|---|---|---|---|
| Number of ports | 整个设计的I/O接口总数 | Combinational area | 组合逻辑占用面积 |
| Number of nets | 设计中所有信号连线的总数 | Buf/Inv area | 缓冲器/反相器占用面积 |
| Number of cells | 使用的标准单元总数 | Noncombinational area | 时序逻辑占用面积 |
| Combinational cells | 组合逻辑单元数量 | Macro/Black Box area | 宏模块占用面积 |
| Sequential cells | 时序逻辑单元(DFF等)数量 | Net Interconnect area | 互连线占用面积 |
| Macros/Black boxes | 宏单元或未综合黑盒数量 | Total cell area | 所有逻辑单元总面积 |
| Buf/Inv | 缓冲器和反相器数量 | Total area | 芯片预估总面积 |
| References | 使用的单元种类总数 |
以下分别是class和NangateOpenCellLibrary综合后的面积报告
Number of ports: 317
Number of nets: 1095264
Number of cells: 1091945
Number of combinational cells: 825553
Number of sequential cells: 266389
Number of macros/black boxes: 0
Number of buf/inv: 333941
Number of references: 53
Combinational area: 1831782.000000
Buf/Inv area: 591049.000000
Noncombinational area: 1865775.000000
Macro/Black Box area: 0.000000
Net Interconnect area: undefined (Wire load has zero net area)
Total cell area: 3697557.000000
Total area: undefinedNumber of ports: 1470
Number of nets: 1042836
Number of cells: 1039404
Number of combinational cells: 773009
Number of sequential cells: 266389
Number of macros/black boxes: 0
Number of buf/inv: 308383
Number of references: 56
Combinational area: 784626.603988
Buf/Inv area: 171791.313006
Noncombinational area: 1205033.954484
Macro/Black Box area: 0.000000
Net Interconnect area: undefined (Wire load has zero net area)
Total cell area: 1989660.558472
Total area: undefined设计规模对比
class相较于 NangateOpenCellLibrary
- 端口急剧减少:class库综合后端口数比NangateOpenCellLibrary库少78%,表明可能存在显著的层次扁平化优化
- 时序单元稳定:寄存器数量完全相同
- 组合逻辑增加:增加了52,544个组合单元(+6.8%),说明class库逻辑效率较低
面积效率对比
class相较于NangateOpenCellLibrary
- 缓冲器效率极低:缓冲器面积暴增两倍,说明class库驱动能力不足
- 组合逻辑效率差:相同功能多用133%面积实现
- 整体面积比NangateOpenCellLibrary_45nm库大80%,说明工艺的提升对芯片面积的缩小至关重要
power_report
由于class虚拟工艺库中缺少必要的功耗模型数据,故只有NangateOpenCellLibrary库的功耗报告
报告各项参数含义
主要功耗类型和功耗分组含义
| Power Group | 包含组件 | 功耗类型 | 含义 |
|---|---|---|---|
| io_pad | I/O焊盘单元 | Internal Power | 单元内部开关功耗 (门电容充放电) |
| memory | RAM/ROM存储单元 | Switching Power | 输出负载开关功耗 (负载电容充放电) |
| black_box | 黑盒模块 | Leakage Power | 静态漏电功耗 (亚阈值电流) |
| clock_network | 时钟树网络 | Total Power | 总功耗 |
| register | 时序单元(FF) | ||
| sequential | 非寄存器时序逻辑 | ||
| combinational | 组合逻辑单元 | ||
| Total | 全设计功耗 |
NangateOpenCellLibrary库功耗报告如下
Cell Internal Power = 92.5732 mW (100%)
Net Switching Power = 75.4386 uW (0%)
---------
Total Dynamic Power = 92.6486 mW (100%)
Cell Leakage Power = 33.3064 mW
Internal Switching Leakage Total
Power Group Power Power Power Power ( % ) Attrs
--------------------------------------------------------------------------------------------------
io_pad 0.0000 0.0000 0.0000 0.0000 ( 0.00%)
memory 0.0000 0.0000 0.0000 0.0000 ( 0.00%)
black_box 0.0000 0.0000 0.0000 0.0000 ( 0.00%)
clock_network 9.2822e+04 0.0000 0.0000 9.2822e+04 ( 73.54%) i
register 2.9062 1.9358 2.0252e+07 2.0257e+04 ( 16.05%)
sequential 4.0215 3.2856e-02 1.7579e+04 21.6331 ( 0.02%)
combinational 8.6750 73.4701 1.3037e+07 1.3119e+04 ( 10.39%)
--------------------------------------------------------------------------------------------------
Total 9.2838e+04 uW 75.4387 uW 3.3306e+07 nW 1.2622e+05 uW总体功耗分布
| 功耗类型 | 数值 | 占比 |
|---|---|---|
| 总功耗 | 126,220 μW | 100% |
| 时钟网络功耗 | 92,822 μW | 73.54% |
| 寄存器功耗 | 20,257 μW | 16.05% |
| 组合逻辑功耗 | 13,119 μW | 10.39% |
可见时钟网络产生的功耗占总功耗的比重较大
原理图对比
打开DC gui,使用design_vision命令
以下分别为class库和NangateOpenCellLibrary库综合后的原理图
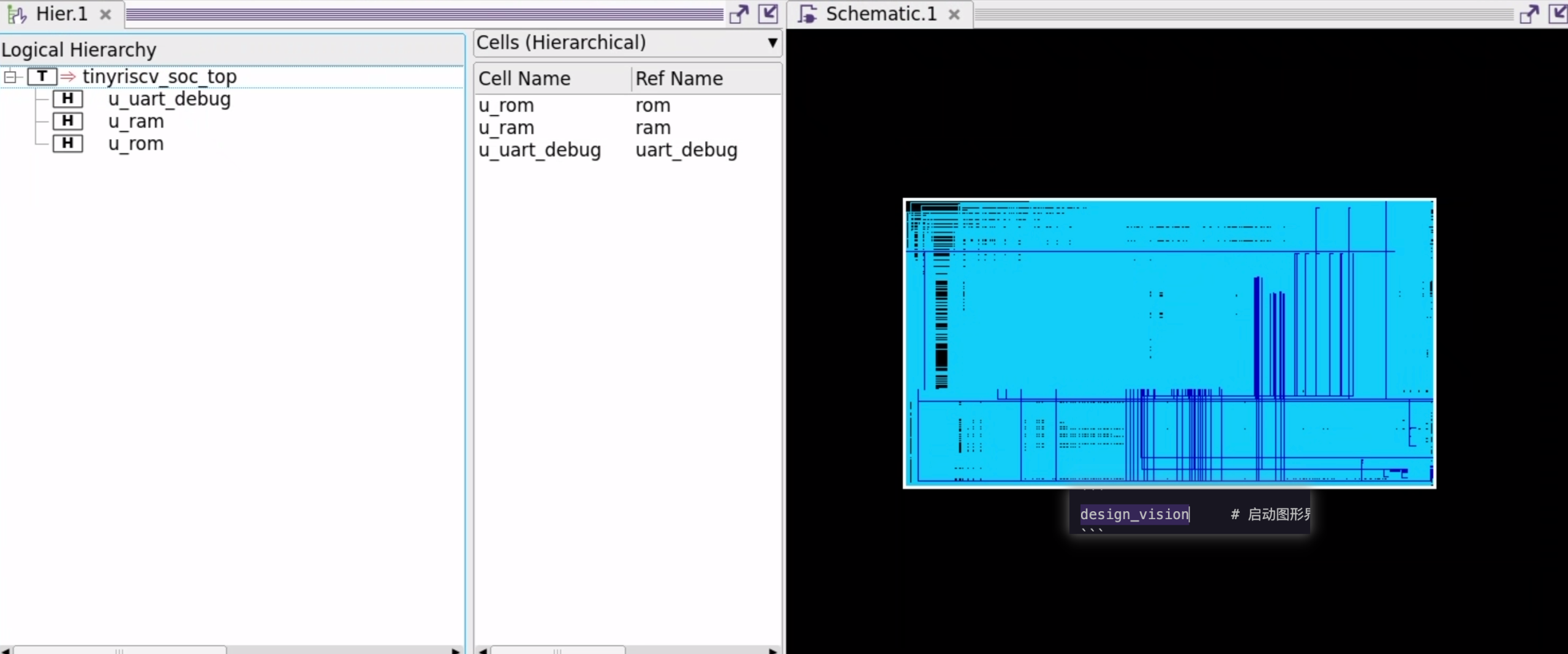
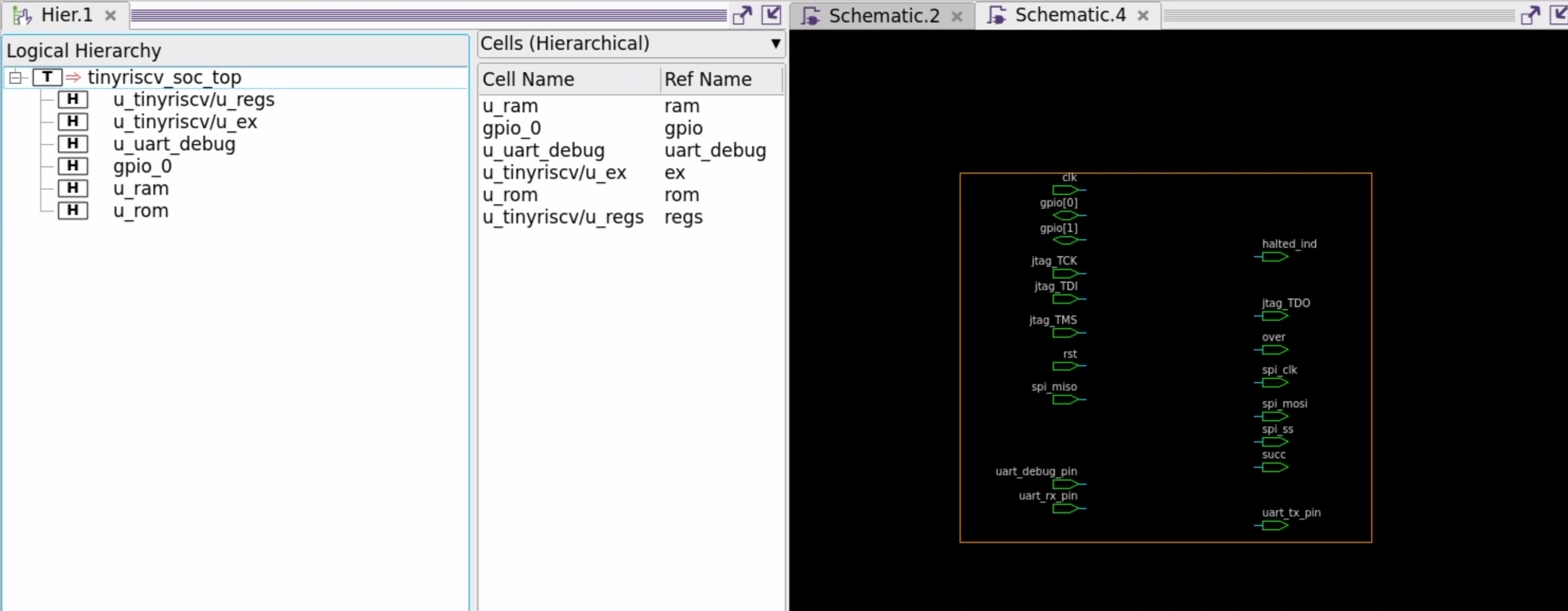
可以发现class库在综合过程中存在显著的层次扁平化优化,也佐证了在对比面积报告时class库综合的端口大量减少的原因
cpu利用率
和FPGA工具vivado不同,DC综合过程中处理器32线程可以满载运行,而vivado在综合过程中顶多跑满几个核心,可见DC工具在性能与多核方面优化的非常好
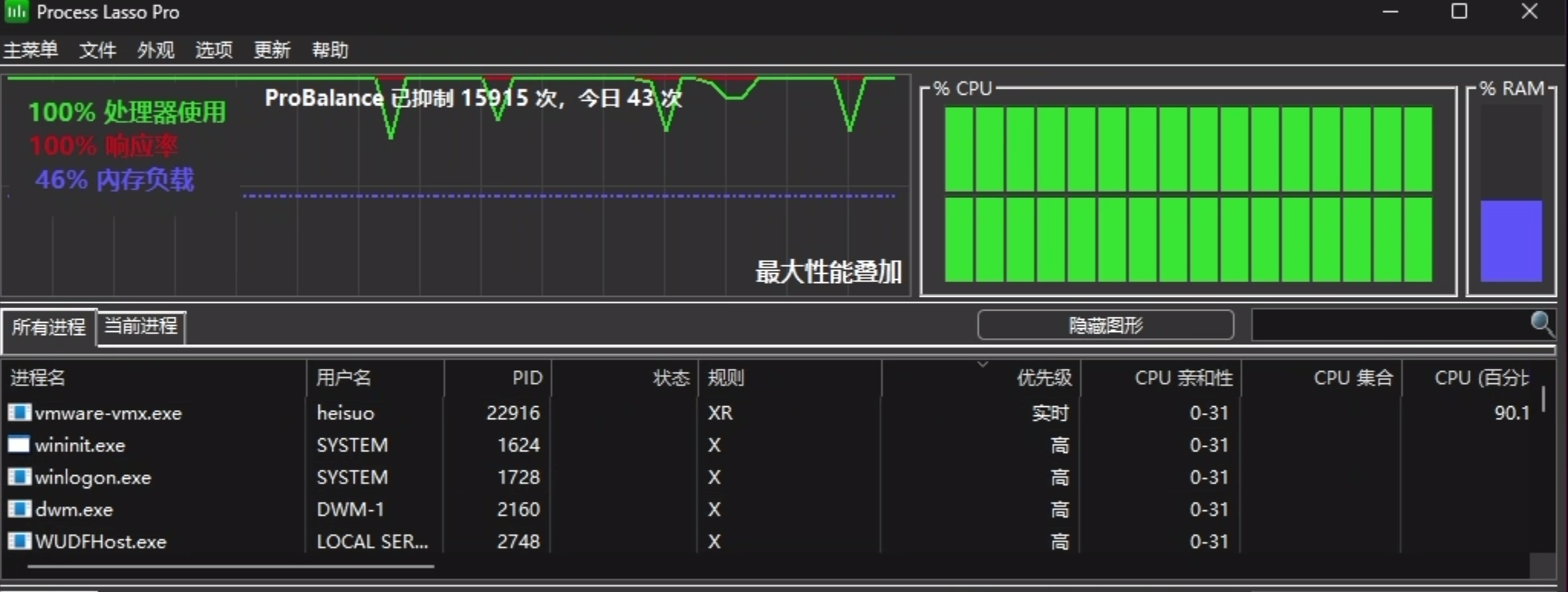
Debug
bug1

问题产生原因:
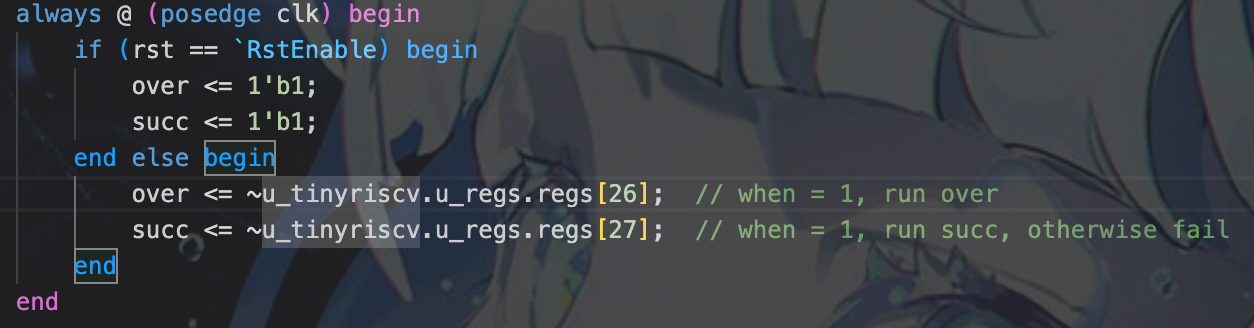
定位到代码报错的部分,发现这里有跨模块引用寄存器模块中的寄存器,导致DC无法找到相应的引用模块
解决办法:重构代码,将寄存器引出
修改后代码如下
// 在regs.v模块中添加
module regs(
// ...其他端口保持不变...
output wire [`RegBus] debug_reg26 , // debug输出
output wire [`RegBus] debug_reg27 , // debug输出
);
reg[`RegBus] regs[0:`RegNum - 1];
assign debug_reg26=regs[26];
assign debug_reg27=regs[27];
// 在tinyriscv.v模块中添加
module tinyriscv(
// ...其他端口保持不变...
output wire [`RegBus] debug_reg26 , // debug输出
output wire [`RegBus] debug_reg27 , // debug输出
);
regs u_regs(
.debug_reg26(debug_reg26),
.debug_reg27(debug_reg27),
...
)
// 在tinyriscv_soc_top.v中的使用
wire [`RegBus] debug_reg26;
wire [`RegBus] debug_reg27;
always @ (posedge clk) begin
if (rst == `RstEnable) begin
over <= 1'b1;
succ <= 1'b1;
end else begin
over <= ~debug_reg26; // when = 1, run over
succ <= ~debug_reg27; // when = 1, run succ, otherwise fail
end
end
tinyriscv u_tinyriscv(
.debug_reg26(debug_reg26),
.debug_reg27(debug_reg27),
...
)bug2
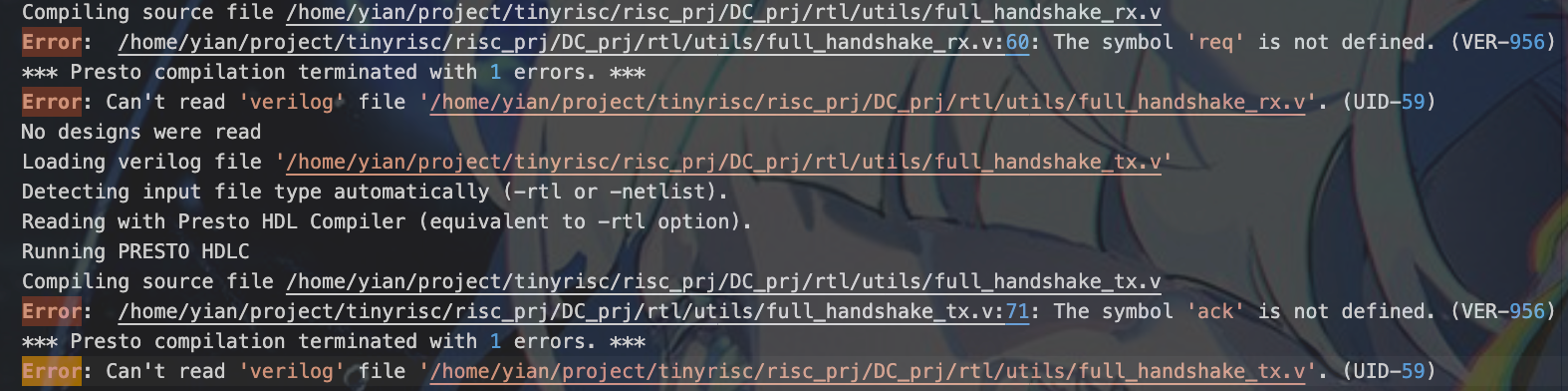
问题产生原因:
req与ack未定义,定位到代码如下,发现req与ack定义到了下方,导致上面的代码无法识别
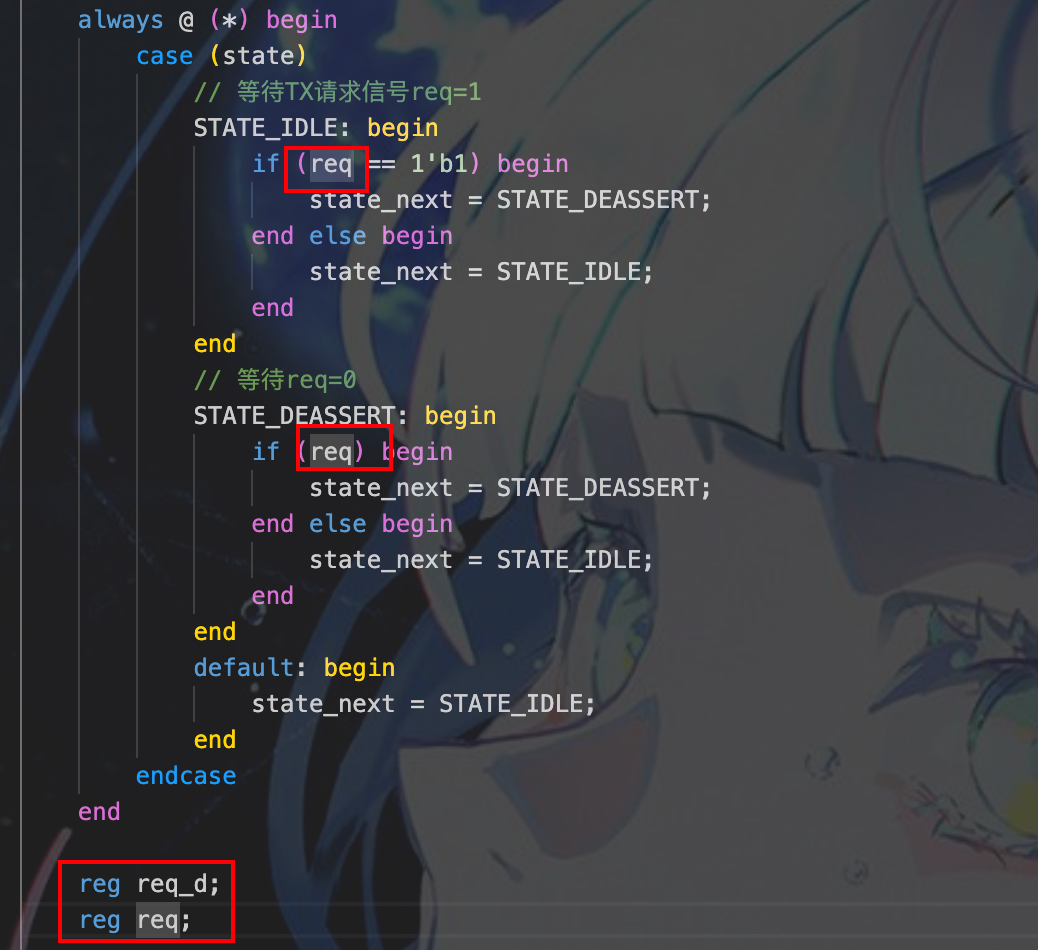
解决办法:将寄存器定义移至最上面
bug3
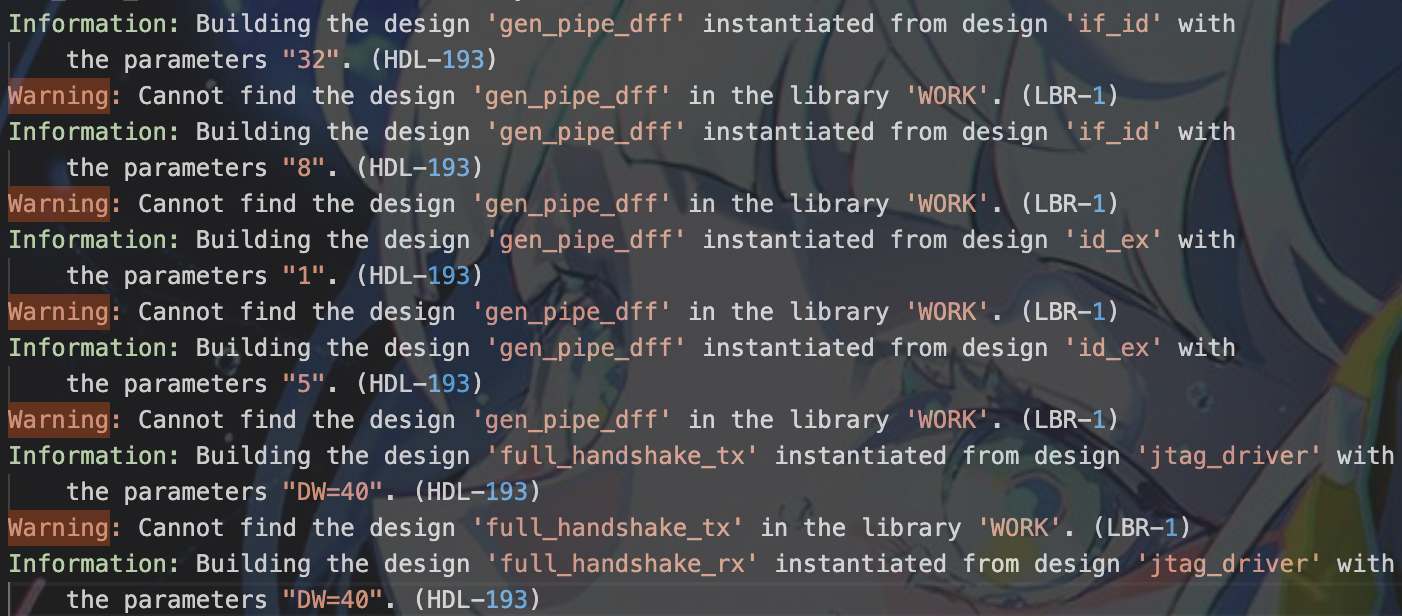
问题产生原因:
带有参数的工程进行综合时,和不带参数时的配置指令是不一样的。不带参数时,直接使用read_verilog + link就可以,后者需要使用analyze -format verilog + elaborate,具体的配置格式修改如下:
解决方法:
# Read design to Dc Memory
#无参数时
set source_file [sh find ./rtl -name "*.v"]
read_file -format verilog $source_file
current_design $top_name
link
uniquify
#有参数时
set work_path work
# 修改中间文件的存储位置
define_design_lib work -path $work_path
# 遍历查找根目录下所有的 Verilog 文件
set source_file [sh find ./rtl -name "*.v"]
analyze -format verilog -lib work $source_file
elaborate $top_name
uniquify总结
本文完成了基本的DC入门操作,并对两种不同工艺库综合结果进行对比,说明不同工艺库在优化方式,时序性能,面积,功耗等方面均有不同,综合来说更为先进的工艺,在时序,面积,功耗等方面均有更大的优势
Comments NOTHING