输入输出端口

如上图所示,左侧的端口均为输入端口,右侧端口均为输出端口,其中,S_AXIS_DATA为输入数据端口,我们要进行FFT的数据需要通过这根线输入给IP核;S_AXIS_CONFIG为输入配置端口,这个信号包含了对数据进行FFT还是IFFT、缩放因子、FFT变换点数等信息;FFT变换后的数据从M_AXIS_DATA端口输出。这些端口的具体功能可以参见pg109手册。
Vivado中IP核的配置
Configuration
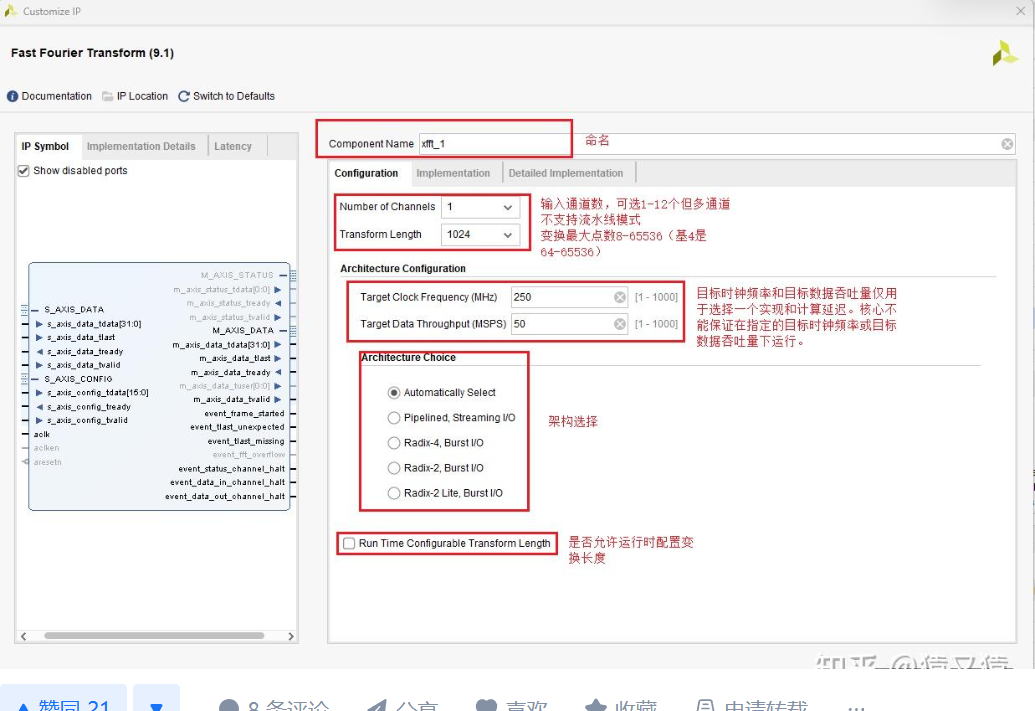
在第一个“Configuration”选项卡中,各参数含义如下:
(1)、“Number of Channels”用来选择 fft 运算的通道数,可选范围为 1~12 通道。这里需要注意的是多通道配置只有在 Burst I/O 才能选。
(2)、“Transform Length”用来选择 fft 运算的采样点个数,这里根据所选架构的不同,采样点的范围也不一样。当架构选为 Pipelined Streaming I/O、 Radix-2 Burst I/O 和 Radix-2 Lite Burst I/O 时,其可选范围为 8~65536 通道。当架构选为 Radix-4 Burst I/O 时,其可选范围为 64~65536 通道。这里需要注意的是采样点个数只能是 2 的次幂。
(3)、“Target Clock Frequency”用来选择 fft 运算的时钟,可选范围为 1MHz~1000 MHz。本次实验
将时钟设置为 100 MHz。
(4)、“Target Data Throughput”用来选择 fft 运算的数据速率,可选范围为 1MSPS~1000 MSPS。这
个选项只有在 Automatically Select 模式下才可配置。
(5)、“Architecture Choice”用来选择 fft 运算的架构,总共有 5 种架构选择,分别是 Automatically Select(自动选择模式)、Pipelined Streaming I/O(并行流水线架构)、Radix-4 Burst I/O(基 4 型 I/O 突发架构)、Radix-2 Burst I/O(基 2 型 I/O 突发架构)和 Radix-2 Lite Burst I/O(基 2 型 I/O 简化突发架构)
下面对这 5 种架构做个简单介绍:
- Automatically Select(自动选择模式):自动选择所需要的 FFT 变化架构;
- Pipelined Streaming I/O(并行流水线架构):这个架构下允许数据连续处理;
- Radix-4 Burst I/O(基 4 型 I/O 突发架构):这个架构下采用迭代方法分别加载和处理数据,它比并行流水线架构下消耗资源更少,但变换时间更长;
- Radix-2 Burst I/O(基 2 型 I/O 突发架构):这个架构下采用 Radix-4 Burst I/O 相同的迭代方法,但蝶形运算更小。这意味着它比Radix-4 Burst I/O 消耗资源更少,但转换时间比 Radix-4 Burst I/O 更长;
- Radix-2 Lite Burst I/O(基 2 型 I/O 简化突发架构):这个架构是 Radix-2 Burst I/O 的一种简化,这种架构采用分时复用的方法来进行更小的蝶型运算,但代价是变换时间比 Radix-2 Burst I/O 更长。本次实验采用Radix-4 Burst I/O 架构。
(6)、“Run Time Configurable Transform Length”用来选择采样点个数是否动态配置,当勾选了这个选项后,上面的 Transform Length 选项将变为不可选状态。本次不勾选该选项。
Implementation
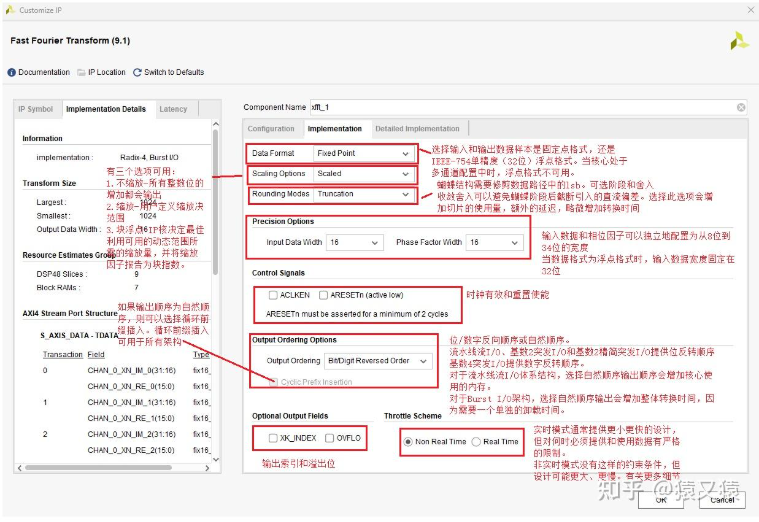
在第二个“Implementation”选项卡中,各参数含义如下:
(1)、“Data Format”用来选择 fft 运算的输入输出数据格式,这个选项有 2 种数据格式可选,分别是Fixed-Point(定点数据格式)和 Floating-Point(浮点数据格式)。 - Fixed-Point(定点数据格式):对于定点输入,输入数据为 N 个复数向量,表示双路 bx-bit 二进制补码,即实部和虚部都为 bx-bit 二进制补码,bx = 8~34,相应地,相位因子 bw 也为 8~34bit 位宽;
- Floating-Point(浮点数据格式):对于单精度浮点输入,输入 N 个复数向量,表示双路 32-bit 浮点数据,相位因子为 24 或者 25bit 定点数。这里有个地方大家注意下,当 fft 运算的通道数为多通道时,浮点数据格式是不可用的
(2)、“Scaling Options”用来选择 fft 运算的缩放格式,这个选项有 3 种缩放格式可选,分别是 Unscaled(全精度不缩放算法)、Block Floating-Point(块浮点)和 Scaled( 定点缩减位宽)。 - Unscaled(全精度不缩放算法):选择这种模式不用担心变化过程中会出现溢出,因为 ip 会将所有的进位都拉到了输出端口。假设输入是 32bit 的话,那么输出是 64bit。
- Scaled( 定点缩减位宽):在这种模式下,fft 运算的缩放因子由用户自己来配置,在 s_axis_config_data中会有相应的字段来配置缩放因子;
- Block Floating-Point(块浮点):在这种模式下,不管输入的格式如何,FFT 变化内部都采用浮点,会根据每一级的的数据情况自动缩放,使数据不出现溢出的情况。
(3)、“Rounding Modes”用来选择 fft 运算输出数据的舍入模式,这种模式是对输出数据的低位进行截断。这个选项有 2 种格式可选,分别是 Truncation(截断模式)和 Convergent Rounding(收敛舍入模式)。 - Truncation(截断模式):这种模式是直接对累加器位宽与输出位宽之差进行舍弃;
- Convergent Rounding(收敛舍入模式):这种模式是向最近的奇数舍入或者最近的偶数舍入。当一个数字的小数部分正好等于二分之一时,如果数字是奇数,收敛四舍五入就会向上舍入,如果数字是偶数就会向下舍入。
(4)、“Input Data Width”用来选择 fft 运算输入数据的位宽,可选范围为 8bit~34bit。当数据格式为Floating-Point 模式时,输入数据宽度固定为 32 位,相位因子宽度可设置为 24 或 25 位。
注意这个位宽是实部或者虚部的位宽,而不是加起来。比如这里设置 16,那总的输入进来的长度就是虚部拼接实部共 32bits
(5)、“Phase Factor Width”用来选择 fft 运算输入相位因子的位宽,可选范围为 8bit~34bit。通常情况下将输入相位因子的位宽与输入数据的位宽设成一样,本次实验设为 9。
(6)、“Control Signals”用来选择 fft 运算是否需要时钟使能和同步复位。如果将 2 个选项同时勾选,同步复位将覆盖时钟使能。如果不选择某个选项,则可以节省一些逻辑资源,并且可以实现更高的时钟频率。这里需要注意的是同步复位的有效长度至少要保持 2 个驱动时钟,否则可能会导致复位不成功。本次实验勾选同步复位,不勾选时钟使能。
(7)、“Output Odering”用来选择 fft 运算输出数据的模式,这个选项有 2 种模式可选,分别是 Bit/Digit Reversed Order(反序输出)和 Natural Order(顺序输出),选择顺序输出。
Bit/Digit Reversed Order(反序输出):按照变化后的顺序直接输出,是倒序输出,需要自己后续处理;
Natural Order(顺序输出): FFT 变化后的输出已经调整了顺序,按照 xk_index 自然顺序列出变化结果
(8)、“Cyclic Perfix Insertion”用来选择 fft 运算是否要循环前缀插入,该选项只在 Natural Order(顺序输出)的模式下可选
(9)、“Optional Output Fields”用来选择 fft 的输出字段,该选项下有 2 种模式可选,分别是 XK_INDEX(输出结果索引)和 OVFLO(溢出指示信号)。 - XK_INDEX(输出结果索引):FFT 变幻的结果索引,在 m_axis_data_user 中有相应的字段;
- OVFLO(溢出指示信号):变换中溢出的指示信号,对应的信号名为 event_fft_overflow。
(10)、“Throttle Schemes”用来选择 fft 运算是否采用节流法案,该选项下有 2 个模式可选,分别是Real Time(实时模式)和 Non-Real Time(非实时模式)。选择非实时模式。 - Real Time(实时模式):实时模式通常提供更小、更快的设计方案,但对用户需要输入数据的时序有严格的限制;
- Non-Real Time(非实时模式):非实时模式没有严格的时序限制,但设计所需的资源更多,运算的速度更慢。
Detailed Implementation
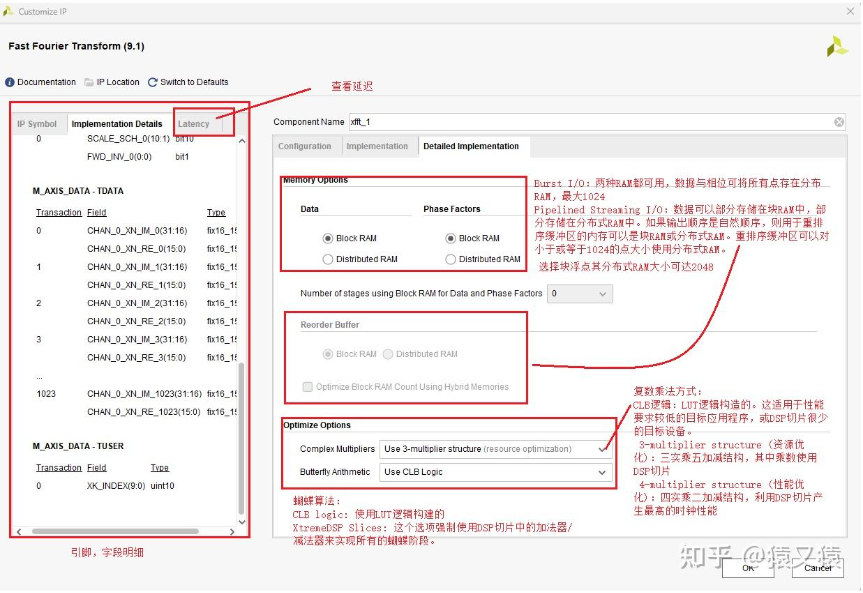
在第三个“Detailed Implementation”选项卡中,各参数含义如下:
(1)、“Memory Options”用来选择 fft 运算的输入数据和输入相位因子存储在哪种 ram,ram 有 2 种可选,分别是 Block RAM(块 RAM)和 Distributed RAM(分布式 RAM)。在 Burst I/O 模式下块 RAM 和分布式 RAM 都可以选择;Pipelined Streaming I/O 模式下是同时使用块 RAM 和分布式 RAM。
(2)、“Reorder Buffer”:该选项只有在运算的架构为 Pipelined Streaming I/O 模式下可选,表示重新排序缓冲区使用哪种 RAM。
(3)、“Optimize Block Ram Count Using Hy brid Memories”:该选项表示如果重新排序缓存区的大小大于一个块 RAM,则由块 RAM 和分布式 RAM 来混合构造重新排序缓冲区,其中大部分数据存储在块 RAM中,剩下的一些存储在分布式 RAM 中 。
(4)、“Complex Multipliers”:这个选项表示复杂的乘法用什么来构造,该选项有 3 种构造方式,分别是 Use CLB logic(使用 CLB 资源)、Use 3-multiplier structure(使用 3 次乘法结构)和 Use 4-multiplier structure(使用 4 次乘法结构)。
- Use CLB logic:所有的乘法器都使用 CLB logic 构造。这选项适用于性能要求不高的程序或者只使用少量 DSP 的程序;
- Use 3-multiplier structure:所有复数乘数都使用 3 个实乘和 5 个加减来构造,其中乘法使用 DSP 片,加减法使用片逻辑。这种结构减少了 DSP 的片数,但多使用了一些片逻辑;
- Use 4-multiplier structure:所有复数乘数都使用 4 个实乘和 2 个加减来构造,乘法和加减法都用 DSP 来实现。这种结构下可以产生最高的时钟性能,但代价是需要更多的 DSP。
(5)、“Butterfly Arithmetic”:这个选项表示蝶形运算用什么来构造,该选项有 2 种构造方式,分别是 Use CLB logic(使用 CLB 资源)和 Use XtremeDSP Slices(使用 XtremeDSP 资源)。 - Use CLB logic:所有的蝶型运算都采用 CLB 资源;
- Use XtremeDSP Slices:该选项强制使用 DSP 中的加法器/减法器实现所有蝶形运算。
Implementation Details
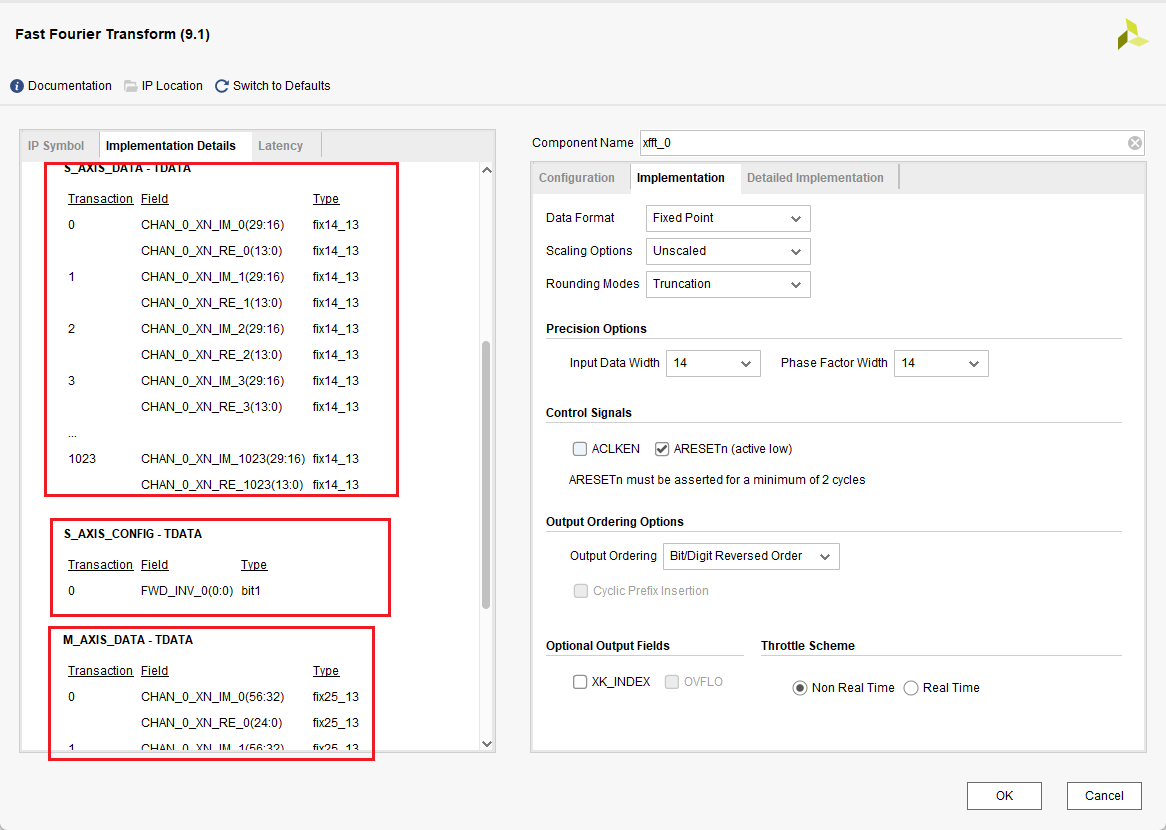
展示了基本的数据格式,资源占用量
其中包含了S_AXIS_DATA_TDATA、S_AXIS_CONFIG_TDATA以及M_AXIS_DATA_TDATA的数据格式,我们需要加以关注:
S_AXIS_DATA_TDATA:共32位,其中低14位为输入数据的实部,高14位为输入数据的虚部(但在实际使用中,高14位才是实部,低14位是虚部)
S_AXIS_CONFIG_TDATA:最低位第0位,决定对数据进行FFT还是IFFT,置1时FFT,清零时IIFT,由于要进行补零操作,因此在最终写入S_AXIS_CONFIG_TDATA时,除了最低位以外,还要再补七个零,补到8位
M_AXIS_DATA_TDATA:64位数据输出,低25位为实部,高25位为虚部
软件生成测试数据
%生成FFT测试信号数据测试IP核
clear
close("all")
% 参数定义
fs = 102400; % 采样率
% T = 0.05; % 采集时间50ms
% N = fs * T; % 总采样点数
N = 1024; % 总采样点数
t = (0:N-1)/fs; % 时间向量
fft_points = 1024;%FFT点数
%% 生成待测试信号并进行14位量化(假设AD的输入值为-3~3)
% 量化参数
Bit=14;%量化位数
num_levels = 2^Bit; % 量化级别
min_val = -3; % 数据的最小值
max_val = 3; % 数据的最大值
% 10kHz锯齿波
f_saw = 1000;
saw_wave = sawtooth(2*pi*f_saw*t) + 0.001*randn(1, length(t));
quantized_saw = round((saw_wave - min_val) / (max_val - min_val) * (num_levels - 1));
%数据写入txt文件
fp = fopen('data_before_fft.txt','w');
for i = 1:N
temp=dec2bin(quantized_saw(i)-2^(Bit-1),16);%负数的位数会变成8的整数倍,所以统一改成16
fprintf(fp,'%s',temp(16-Bit+1:16));%只打印[13:0]位的数据
fprintf(fp,'rn');
end
fclose(fp);
%fft结果对比
y = fft(quantized_saw-2^(Bit-1),N);
仿真测试
结果
整体仿真链路如下
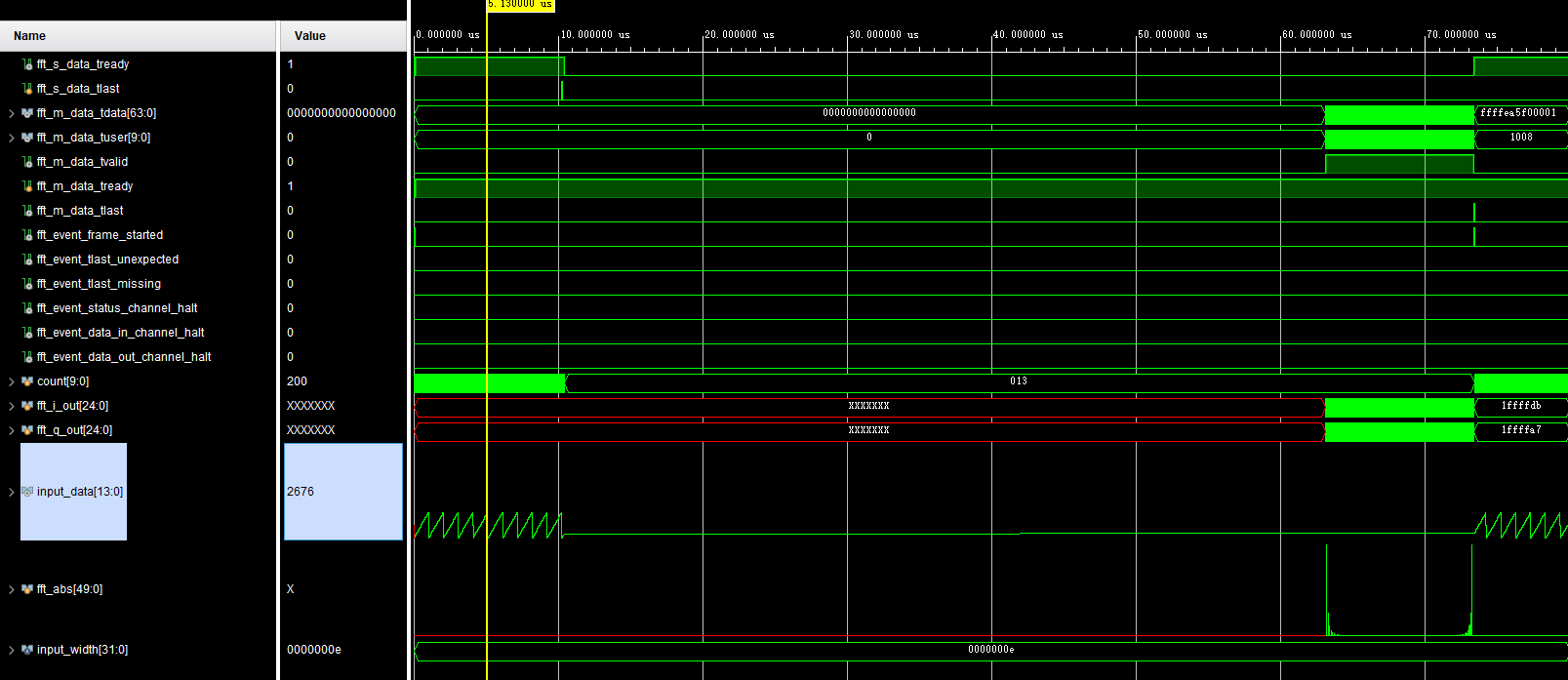
fft_m_data_tuser代表FFT点位,100MHz频率下,输入1Khz锯齿波,经过70us的计算,在第12个点出现基波,第22个点出现2次谐波,第32个点出现3次谐波(在时序上有两个周期的延迟),幅度比为9:4:1,功率谱符合锯齿波的频域特点
代码
FFT_test2.v
`timescale 1ns / 1ps
module FFT_test2();
parameter input_width = 14;
reg clk;
reg rst_n;
reg signed [input_width-1:0] Time_data_I[1023:0];
reg data_finish_flag;
wire fft_s_config_tready;
reg signed [31:0] fft_s_data_tdata;
reg fft_s_data_tvalid;
wire fft_s_data_tready;
reg fft_s_data_tlast;
wire signed [63:0] fft_m_data_tdata;
wire signed [9:0] fft_m_data_tuser;
wire fft_m_data_tvalid;
reg fft_m_data_tready;
wire fft_m_data_tlast;
wire fft_event_frame_started;
wire fft_event_tlast_unexpected;
wire fft_event_tlast_missing;
wire fft_event_status_channel_halt;
wire fft_event_data_in_channel_halt;
wire fft_event_data_out_channel_halt;
reg [9:0] count;//$clog函数用于计算位宽
reg signed [24:0] fft_i_out;
reg signed [24:0] fft_q_out;
wire signed[input_width-1:0]input_data; //提取输入信号,便于观察
assign input_data = fft_s_data_tdata[29:16];
reg signed [49:0] fft_abs;//功率谱
initial begin
clk = 1'b1;
rst_n = 1'b1;
#1
rst_n = 1'b0;
fft_m_data_tready = 1'b1;
$readmemb("C:/heisuo/project/FPGA/ji_fen_sai1/FFT_test/data_before_fft.txt",Time_data_I);
#80_000
$finish;
end
always #5 clk = ~clk;
//信号输入
always @ (posedge clk or negedge rst_n) begin
if(!rst_n) begin
fft_s_data_tvalid <= 1'b0;
fft_s_data_tdata <= 32'd0;
fft_s_data_tlast <= 1'b0;
data_finish_flag <= 1'b0;
count <= 10'd0;
rst_n = 1'b1;
end
else if (fft_s_data_tready) begin
if(count == 10'd1023) begin
fft_s_data_tvalid <= 1'b1;
fft_s_data_tlast <= 1'b1;
fft_s_data_tdata <= {2'd0,Time_data_I[count],16'd0};//虚部为0
count <= 10'd0;
data_finish_flag <= 1'b1;
end
else begin
fft_s_data_tvalid <= 1'b1;
fft_s_data_tlast <= 1'b0;
fft_s_data_tdata <= {3'd0,Time_data_I[count],16'd0};
count <= count + 1'b1;
end
end
else begin
fft_s_data_tvalid <= 1'b0;
fft_s_data_tlast <= 1'b0;
fft_s_data_tdata <= fft_s_data_tdata;
end
end
always @ (posedge clk) begin
if(fft_m_data_tvalid) begin
fft_i_out <= fft_m_data_tdata[24:0];//实部数据
fft_q_out <= fft_m_data_tdata[56:32];//虚部数据
end
end
always @ (posedge clk) begin
fft_abs <= $signed(fft_i_out)* $signed(fft_i_out)+ $signed(fft_q_out)* $signed(fft_q_out);
end
//fft ip核例化
xfft_0 u_fft(
.aclk(clk), // 时钟信号(input)
.aresetn(rst_n), // 复位信号,低有效(input)
.s_axis_config_tdata(8'd1), // ip核设置参数内容,为1时做FFT运算,为0时做IFFT运算(input)
.s_axis_config_tvalid(1'b1), // ip核配置输入有效,可直接设置为1(input)
.s_axis_config_tready(fft_s_config_tready), // output wire s_axis_config_tready
//作为接收时域数据时是从设备
.s_axis_data_tdata(fft_s_data_tdata), // 把时域信号往FFT IP核传输的数据通道,[29:16]为虚部,[13:0]为实部(input,主->从)
.s_axis_data_tvalid(fft_s_data_tvalid), // 表示主设备正在驱动一个有效的传输(input,主->从)
.s_axis_data_tready(fft_s_data_tready), // 表示从设备已经准备好接收一次数据传输(output,从->主),当tvalid和tready同时为高时,启动数据传输
.s_axis_data_tlast(fft_s_data_tlast), // 主设备向从设备发送传输结束信号(input,主->从,拉高为结束)
//作为发送频谱数据时是主设备
.m_axis_data_tdata(fft_m_data_tdata), // FFT输出的频谱数据,[56:32]对应的是虚部数据,[25:0]对应的是实部数据(output,主->从)。
.m_axis_data_tuser(fft_m_data_tuser), // 输出频谱的索引(output,主->从),该值*fs/N即为对应频点;
.m_axis_data_tvalid(fft_m_data_tvalid), // 表示主设备正在驱动一个有效的传输(output,主->从)
.m_axis_data_tready(fft_m_data_tready), // 表示从设备已经准备好接收一次数据传输(input,从->主),当tvalid和tready同时为高时,启动数据传输
.m_axis_data_tlast(fft_m_data_tlast), // 主设备向从设备发送传输结束信号(output,主->从,拉高为结束)
//其他输出数据
.event_frame_started(fft_event_frame_started), // output wire event_frame_started
.event_tlast_unexpected(fft_event_tlast_unexpected), // output wire event_tlast_unexpected
.event_tlast_missing(fft_event_tlast_missing), // output wire event_tlast_missing
.event_status_channel_halt(fft_event_status_channel_halt), // output wire event_status_channel_halt
.event_data_in_channel_halt(fft_event_data_in_channel_halt), // output wire event_data_in_channel_halt
.event_data_out_channel_halt(fft_event_data_out_channel_halt) // output wire event_data_out_channel_halt
);
endmodule
Comments 1 条评论
Hi there, i read your blog occasionally and i own a similar one and i
was just curious if you get a lot of spam feedback? If so how do
you protect against it, any plugin or anything you can recommend?
I get so much lately it’s driving me crazy so any help is very much appreciated.